
Hermes Agent & Co: Die Boten der Götter und des Chaos
Die Natur von KI-Agenten
Man kann KI-Agenten als ein kybernetisches Zusammenspiel aus starrem Code und fluiden mathematischen Räumen begreifen. Bezeiten gleichen sie eher einem vollkommenen nicht-linearen, chaotischen System.
Die äußere Hülle des Agenten ist ein beliebig komplizierter Zustandsautomat, der in deterministischem Code geschrieben ist. Dieser Code speist sich zur Laufzeit aus Signalen der Umwelt (Perzeption), verwaltet ein (mehr oder minder) strukturiertes, persistentendes Gedächtnis (Memory) und triggert Befehle oder produziert Output (Aktionen).
Das Herzstück in diesem System ist jedoch das generative Modell (bzw. verschiedene Modelle). Der Code nimmt den aktuellen Zustand des Systems und verwebt ihn im Kontext als Prompt in das Modell. Dieses Modell übersetzt den Input in die fließenden Koordinaten eines gigantischen, multidimensionalen Vektorraums, wodurch die Konzepte der Sprache in reine Geometrie transformiert werden. Erst dort, in den geometrischen Beziehungen dieser hyperdimensionalen Landschaft, findet während der Inferenz – dem „magischen“ Vorhersagevorgang des Modells – das Reasoning statt: Das Modell navigiert suchend durch diesen Vektorraum der Wahrscheinlichkeiten, um die nächste sinnvolle Entscheidung zu berechnen, die es dann als Signal an das Code-Exoskelett und den Systemzustand zurückgibt. Kontinuierliche Feedbackschleifen (Reward) verändern dabei überdies die Gewichtungen aller Entscheidungen und damit die Art und Weise, wie der Code und der magische Raum miteinander interagieren.
Durch die inhärente und fundamentale Nicht-Linearität sind Agenten Systeme, die sich zunächst per Definition der Vorhersagbarkeit und Kontrolle entziehen. Der Code für sich genommen ist zwar berechenbar, aber da er bei jedem Schritt über das Embedding die unendlichen, probabilistischen Pfade der modellseitigen Inferenz konsultiert, liefert das Gesamtsystem keine garantierten oder erwartbaren Ergebnisse. Dieses Chaos ist kein Programmierfehler, sondern ihr tieferes Wesen.
Das Komplexitäts-Spektrum von Agentensystemen ist gewaltig: Es reicht von einfachen Workflows, bei denen der Code dominiert und das Modell nur als bessere Wenn-Dann-Weiche nutzt, die einen Text produziert, bis hin zu hochkomplexen Runtime-Systemen, bei denen der Code nur noch eine hauchdünne Membran um eine Modell-Ebene darstellt. Eine Ebene, die den multidimensionalen Vektorraum so dezent umkleidet, dass im Beobachter unweigerlich das faszinierende – und manchmal unheimliche – Gefühl einer eigenwilligen, fast lebendigen Entität mit Intention entsteht.
Agenten sind kein konkretes Ding, sondern nur unterschiedlich komplexe Systeme mit potenziell extrem chaotischen Zuständen. Das macht sie für uns Menschen vielleicht so interessant – denn sie sind nicht-deterministisch, keine Dampflok, sondern emergent; sie entstehen als Zustand. Sie sind nicht vorhersagbar, sondern eventuell überraschend. Sie erinnern uns an unser Wesen.
2026: Der Run auf autonome Agenten
Auch aufgrund des Überraschungserfolgs von OpenClaw sind „autonome“, „proaktive“ und „Always-On“-Agenten zu einem massiven Hype geworden. Der Markt bewegt sich 2026 endgültig weg von passiven Chatbots hin zu proaktiven, autonomen Agenten. Diese Systeme laufen als permanente Hintergrundprozesse auf Servern oder in isolierten Cloud-Umgebungen und arbeiten unterschiedlich komplexe Workflows ab – theoretisch rund um die Uhr, also auch während der Nutzer offline ist.
Zum besseren Überblick lohnt sich eine kurze Bestandsaufnahme: Wer arbeitet an solchen Agenten und welche technologischen Ansätze gibt es aktuell?
1. Big-Tech und KI-Giganten
Die Branchenriesen und Platzhirsche in der KI-Entwicklung sind überall an vorderster Front dabei – von Microsoft und Google über Amazon und OpenAI bis hin zu Anthropic. Während es dem einen um Compute geht, stehen für den anderen Modelle oder skalierbare Enterprise-Services im Fokus. Sobald der Trend jedoch in Richtung Agenten umschlägt, müssen alle Akteure ihre Ökosysteme anpassen.
- OpenAI Operator : Anfang 2025 ausgerollt, ist Operator das Paradebeispiel für einen超autonomen Browser-Agenten. Er übernimmt mehrstündige Alltagsrecherche- und Buchungsprozesse komplett selbstständig in einer geschützten Cloud-Sandbox.
- Google (Viel Bewegung vor der I/O): Google hat pünktlich im Mai seine gesamte Agenten-Strategie umgeworfen. Das experimentelle, screenshotbasierte Browser-Tool Project Mariner wurde nach 17 Monaten Laufzeit im Mai 2026 offiziell beerdigt. Grund: Die visuelle Web-Steuerung war zu rechenintensiv und fehleranfällig. Dafür kochen nun die Leaks hoch: Interne Berichte enthüllten Tests zu einem tief integrierten Agenten namens Remy , während zeitgleich frische Onboarding-Screens zu Gemini Spark die Gerüchteküche um einen permanenten 24/7-Assistenten anheizen. Zudem schaltete Google am 12. Mai seinen visuell agierenden „Computer-Use-Agent“ im neuen Gemini Intelligence Framework live und bringt die visuelle Steuerung damit sogar direkt auf Smartphones.
- Anthropic: Mit der fortlaufenden Skalierung der Claude-Modelle wird auch deren Agenten-Infrastruktur massiv ausgebaut. Da Agenten für komplexe Workflows primär verlässliche Reasoning-Modelle benötigen und das hauseigene Tool Claude Code als CLI-Ansatz extrem erfolgreich gestartet ist, bleibt Anthropic einer der wichtigsten Innovationstreiber im Markt.
- Microsoft (Azure & Copilot Studio): Als Cloud-Provider, Großaktionär und Enterprise-Software-Gigant besetzt Microsoft alle strategichen Schnittstellen. Um die KI tief im Betriebssystem zu verankern, kündigte Microsoft jüngst für Anfang Juni 2026 den Rollout eines einheitlichen, systemweiten Tastenkürzels (
Alt + C/F6) sowie neuer Interface-Elemente wie einer „Anker“-Funktion an. Das Geld wird zwar insgesamt noch woanders verdient, doch strategisch zieht Redmond hier alle Register. - Amazon (AWS & Bedrock): Amazon fokussiert sich primär auf die Stärkung seines Cloud- und Shopping-Ökosystems. Bemerkenswert sind hierbei die Vorstöße von Amazon WorkSpaces , bei denen KI-Agenten Legacy-Anwendungen rein visuell per Mausklick und Tastatursteuerung ohne API-Anbindung bedienen. Parallel dazu professionalisiert Amazon das Enterprise-Infrastruktur-Deployment über AgentCore und treibt neue KI-Strategien im Online-Shopping voran, in denen Alexa eine zentrale Rolle einnimmt.
Diese Liste lässt sich nahtlos um Schwergewichte wie Nvidia, Meta oder führende chinesische Tech-Konzerne erweitern. Fest steht: Die Strategien von Big Tech unterscheiden sich fundamental von denen agiler Startups oder quelloffener Community-Projekte. Es ist eben etwas anderes, ein weltweites Plattform-Ökosystem umzubauen, als eine punktuelle, hochspezialisierte Lösung zu entwickeln. An dieser Entwicklung kommt im Jahr 2026 niemand mehr vorbei.
2. Die autonomen Startup-Pioniere
Abseits der Konzerne treiben hochinnovative Startups den Markt mit schlüsselfertigen, autonomen Komplettlösungen voran:
- Manus AI: Der absolute Überraschungserfolg seit 2025. Manus stellt für jeden erteilten Task eine eigene, isolierte virtuelle Maschine (VM) bereit. Das System erstellt eigenständig Marktanalysen, schreibt Code und liefert fertige Ergebnisse asynchron per Benachrichtigung aus.
- Devin (Cognition Labs): Die unangefochtene Benchmark für autonomes 24/7-Software-Engineering. Devin loggt sich eigenständig in Jira oder GitHub ein, analysiert und debuggt komplexe Codebases über Nacht und bereitet fertige Pull Requests vor.
3. Die quelloffenen 24/7-Runtimes (OpenClaw- & Hermes-Klasse)
Wer die vollständige Datensouveränität behalten und eine permanente “Always-On”-Umgebung auf dem eigenen Server oder Desktop betreiben möchte, greift zu autonomen Open-Source-Runtimes:
- OpenClaw: Der virale Community-Pionier, initiiert vom österreichischen Entwickler Peter Steinberger (der im Februar 2026 zu OpenAI wechselte). OpenClaw nistet sich als persistenter Hintergrundprozess ein, besitzt einen zyklischen „Heartbeat“-Trigger und lässt sich dezentral per WhatsApp, Signal oder Telegram steuern.
- Hermes Agent: Dazu später mehr …
- ZeroClaw / NanoClaw: Minimalistische, sicherheitsfokussierte Spinoffs aus der Community. Während ZeroClaw als ultrakompakte Rust-Binary für ressourcenarme VPS-Server optimiert ist, isoliert NanoClaw jeden einzelnen Chat-Workspace in strikt abgeschotteten Linux-Containern.
4. Die Coding-Platzhirsche (AI-Native Entwicklung)
Da die Code-Generierung einer der kontextintensivsten und am frühesten kommerziell validierten Anwendungsfälle ist, waren autonome Agenten hier besonders schnell marktreif. An dieser Front verschwimmen die Grenzen zwischen klassischen Editoren und eigenständig agierenden Systemen derzeit am schnellsten:
Die proprietären AI-IDEs (Vollwertige Editoren)
- Cursor: Der unangefochtene, proprietäre Marktführer unter den AI-native Editoren (auf VS-Code-Basis) mit tiefer Codebase-Indizierung und starkem Agenten-Modus. Für ein wirtschaftliches Beben sorgte die Meldung, dass sich SpaceX eine exklusive Kaufoption auf Cursor für astronomische 60 Milliarden Dollar gesichert hat , um die Technologie mit dem xAI-Ökosystem und dem Colossus-Supercomputer zu verschmelzen.
- Windsurf: Einer der stärksten Cursor-Gegenspieler. Windsurf (inzwischen von Cognition AI übernommen ) erlaubt das flüssige Ineinandergreifen von smarter Code-Vervollständigung und autonomen Cloud-Agenten inklusive nativer Devin-Integration.
- GitHub Copilot (Microsoft): Der Pionier der assistierten Programmierung. Als tief integrierte Erweiterung für VS Code und Visual Studio fokussiert er sich nach wie vor stark auf Inline-Vorschläge und chatbasierte Assistenz im laufenden Betrieb, zieht mit komplexeren Enterprise-Workflows aber massiv nach.
Die Terminal- & CLI-Revolution
- Claude Code von Anthropic: Kein grafischer Editor, sondern ein hochgradig agentisches CLI-Tool direkt für die Konsole. Claude Code arbeitet nach der Unix-Philosophie: Er durchsucht eigenständig lokale Repositories, führt Test-Suites aus, behebt Bugs und schreibt Git-Commits autark auf Systemebene.
- OpenCode: Der extrem populäre, quelloffene CLI-Gegenentwurf zu Claude Code. OpenCode läuft im Terminal oder als TUI (Terminal User Interface), ist komplett modellagnostisch und erlaubt Entwicklern maximale Anpassung an eigene lokale Workflows.
- GitHub Copilot in the CLI (gh copilot): Microsofts Brücke in die Konsole. Als native Erweiterung für die GitHub-CLI übersetzt es natürliche Sprache direkt in der Shell in komplexe Bash-/Zsh-Befehle, erklärt Skripte und automatisiert Git-Abläufe.
Open-Source & BYOK (Bring Your Own Key)
- Zed: Das Open-Source-Highlight (komplett in Rust geschrieben und GPU-beschleunigt). Zed versteht sich als das ultimative „Agent Cockpit“. Über das offene Agent Client Protocol (ACP) lassen sich externe Agenten wie Claude Code oder OpenCode direkt in den Editor-Buffer einbinden – inklusive nativer MCP-Server-Unterstützung und des hauseigenen Open-Weight-Modells Zeta.
- Kilo Code: Ein mächtiger Open-Source-Coding-Agent, der als Erweiterung für VS Code und JetBrains-IDEs fungiert. Kilo bricht komplexe Aufgaben über einen integrierten „Orchestrator Mode“ in Teilprozesse auf und unterstützt über 500 KI-Modelle via „Bring Your Own Key“.
5. Die Agent-Stacks und SDKs
Ergänzend dazu gibt es die programmatischen Werkzeugkästen. Hierbei handelt es sich nicht um fertige Endnutzer-Programme, sondern um die Code-Infrastruktur, mit der Entwickler eigene logische Agenten-Strukturen weben:
- LangGraph: Der Industriestandard für komplexe, zustandsorientierte Multi-Agenten-Graphen mit Fokus auf Validierung und zyklische Workflows.
- CrewAI: Extrem beliebt für das schnelle Aufsetzen rollenbasierter Agenten-Teams, die im Hintergrund kollaborieren.
- PydanticAI: Der Favorit für Enterprise-Anwendungen, die strikte Typsicherheit und Datenvalidierung in Python-basierten Agenten-Workflows erzwingen.
Dieses Spektrum an agentischen Ansätzen lässt sich mannigfaltig erweitern. Immer mehr Projekte adressieren gezielt die klassische „Desktop Workforce“ und etablieren neue Frameworks. In diesem Artikel richten wir den Fokus nun auf die praktische Eignung im Alltag und beleuchten im Detail den Hermes Agent von Nous Research – ein Projekt, das die Entwickler wie folgt beschreiben:
„The self-improving AI agent built by Nous Research. The only agent with a built-in learning loop — it creates skills from experience, improves them during use, nudges itself to persist knowledge, and builds a deepening model of who you are across sessions.“ (via Nous Research )
Was ist der Hermes Agent?
Hermes Agent ist eventuell etwas vergleichbar mit OpenClaw. Hinter Hermes steckt Nous Research. Nous Research entstand Ende 2022 nicht als klassisches Silicon-Valley-Unternehmen, sondern als ein dezentrales Grassroots-Kollektiv von KI-Entwicklern und Open-Source-Forschern, die sich organisch über Discord formierten. Hinter dem Projekt stehen maßgeblich die Gründer Jeffrey Quesnelle (in der Entwickler-Szene bekannt als Teknium) und Karan Malhotra, getragen von einer hochaktiven globalen Community. Ein nettes Interview mit Jeffrey Quesnelle kann man hier sehen. Das erklärte Ziel von Nous Research ist es, ein transparentes, frei zugängliches Gegengewicht zu den geschlossenen Systemen der Tech-Giganten zu bilden – eine Philosophie, aus der nun auch die autonome Runtime ihres Hermes Agents hervorgegangen ist. Damit: ein natürlicher Kandidat für einen Test im MonkeyLab :)

Scanning Hermes
Der Agent von Nous Research kann also auf einem Rechner installiert werden und läuft dann. Das durchaus etwas markige Versprechen von Hermes ist, dass er sich selbst verbessert und stetig lernen kann. Das Konzept dahinter ist neben Memory etwa ein Lern-Loop, der es dem Agenten ermöglichen soll, aus Erfahrungen zu lernen und sich an neue Situationen und den Nutzer immer weiter anzupassen. Positiv fand ich übrigens auch, dass Hermes Mechanismen für Kontext-Kompression mitbringt.
Wie inzwischen üblich, kann Hermes über Plug-ins, Skills, Tools und Integrationen erweitert werden. Da man den Code selbst erweitern kann, bietet sich hier grundsätzlich eine große Flexibilität. Zudem können diverse Modell-Provider konfiguriert werden, was den Agenten zunächst Modell-agnostischer aufstellt. Mit dem Agenten kann man via CLI interagieren. Darüber hinaus gibt es ein wirklich gut sortiertes Dashboard, über welches Einstellungen und Konfigurationen vorgenommen werden können. Im Vergleich zu OpenClaw wirkt Hermes tendenziell handzahm und aufgeräumt – dies ist aber nur mein persönlicher Eindruck auf Basis der bisherigen Tests. Heute ganz normal: Via MCP kann man die Möglichkeiten des Agenten erweitern. Die Community um Hermes herum ist nicht so groß wie bei OpenClaw, aber es gibt sehr viele Erweiterungen und Bewegung. Die Dokumentation ist in Ordnung.
Für technisch affine Leute ist die Installation relativ einfach und die CLI bietet eine gute Kontrolle. Wie bei vielen Projekten gibt es auch ein Skript, um sich das Ganze mit einem Einzeiler zu installieren. Aber (!) – bei Thematiken wie dieser ist es sinnvoll, Dokumentationen zu lesen, sich auch mal den Code anzuschauen und zu verstehen, was da grundsätzlich passiert. Technisch nicht-affinen Personen würde ich gegenwärtig die Installation von Agenten, die 24/7 laufen, nicht empfehlen. Agenten können (je nach Einrichtung) viel Geld verbrennen, Daten lesen/verändern/löschen und um den Globus schicken. Ein isoliertes System, eine überlegte Konfiguration und die initiale Risikoabschätzung sind probate und an dieser Stelle empfohlene Maßnahmen.
Das GitHub-Repo des Hermes Agent findet man hier .
Mein Eindruck von Hermes
Ich halte Hermes für ein durchaus gutes Agent-Design, das sich gut für verschiedene Anwendungsfälle eignet. Die Flexibilität und die Möglichkeit, verschiedene Modelle und Tools zu integrieren, machen ihn zu einer interessanten Option. Das jeweilige Setup und die konkrete Konfiguration, die angebundenen Modelle, die individuelle Benutzung und vieles andere führen zu unterschiedlichen Ergebnissen. Agenten-Setups sind kein Tool wie ein einfacher Texteditor. Agenten wie Hermes haben viele dynamische Anteile; ihre „Performance“ bzw. die Lösungsqualität von Aufgaben hängt von vielen Parametern ab. Neutral bewerten kann man lediglich die Konzepte, die bei der Architektur und der Implementierung zugrunde gelegt wurden. Hermes macht hier einen guten ersten Eindruck auf mich. Das bedeutet aber nicht, dass ich mit jedem Output des Agents zufrieden wäre.
Setup
Meine bisherigen Tests basieren auf einem Setup, das nicht allgemein übertragbar ist, aber eventuell dem einen oder anderen als Ausgangspunkt für die eigene Einrichtung dienen kann. Ich habe Hermes auf einer dedizierten Linux-Maschine via Docker Compose installiert und ein paar Anpassungen in der Konfiguration vorgenommen. Z.B. habe ich noch eine SearXNG-Instanz, Chromium und Playwright hinzugefügt, um ein wenig mehr Web-Interaktion zu ermöglichen.
Wichtig war mir bei dem Setup generell:
- Grundlegende Sicherheitsaspekte im Setup und der Konfiguration
- Die Verwendung von lokalen LLMs (z. B. Ollama) neben Cloud-Modellen (in meinem Fall Mistral)
- Der Zugriff im Netzwerk (so dass ich z. B. von einem anderen Rechner das Dashboard aufrufen kann)
- Die Integration (via MCP) von selbstgehosteten Tools und Services (die also auf einem Server laufen)
- Als „universellen“ Kanal für Kommunikation habe ich zusätzlich Telegram vorgesehen, um auch von unterwegs oder anderen Geräten mit dem Agenten zu kommunizieren
Resultierend ist der Aufbau in etwa so:
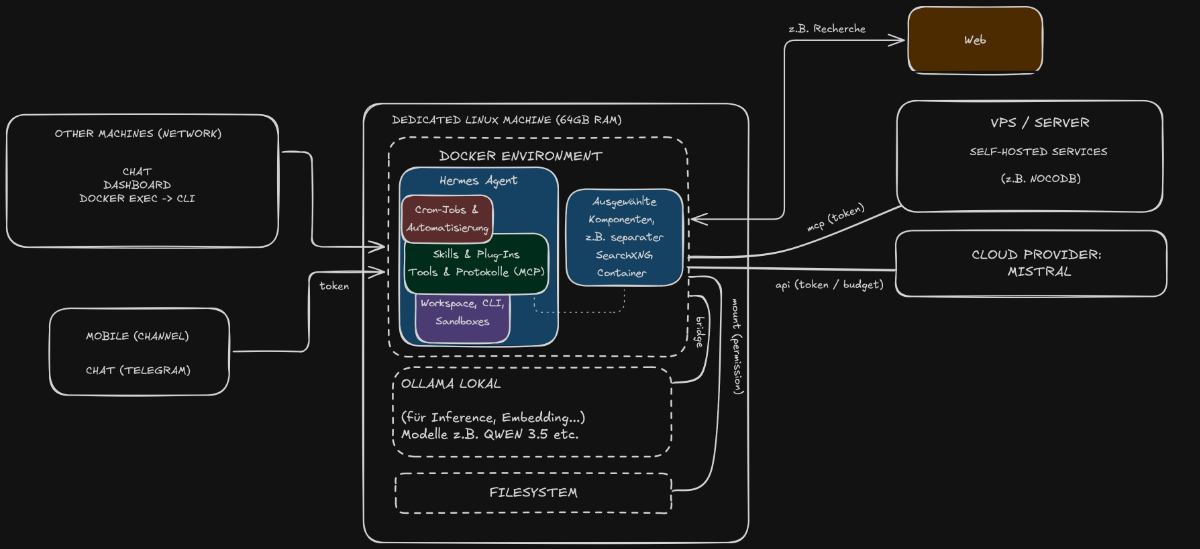
Lokales Hermes Setup (schematisch)
Neben dem initialen Setup muss man sich durch die Konfiguration wühlen. Bei Agenten-Systemen kann das komplex werden. Einige Dinge benötigt man von Anfang an, z. B. den Zugriff auf ein geeignetes Sprachmodell. Hierfür sollte man sich direkt einen sicheren Weg überlegen, wie Credentials / Token verwaltet werden. Das Hermes-Setup führt einen gut durch die nötigen Einstellungen, in denen man sowohl Provider als auch Modelle wählen kann. Mistral war jedoch nicht in der Liste; hierfür habe ich ein paar Anpassungen gemacht. Ich wollte zusätzlich Ollama für lokale Modelle verwenden. Ollama kann man generell über eine Custom-Provider-Einstellung anbinden. In Kombination mit Docker muss man zusätzlich darauf achten, nicht localhost:11434/v1 zu verwenden, sondern host.docker.internal:11434/v1 (auf Mac/Windows mit Docker Desktop) oder 172.17.0.1:11434/v1 (die Docker-Bridge-Gateway-IP auf Linux), wenn Ollama außerhalb des Docker-Containers läuft. Hintergrund: localhost innerhalb eines Containers verweist auf den Container selbst, nicht auf den Host.
Und dann geht es um nicht weniger als die Seele: Markdown-Dateien wie eine SOUL.md werden verwendet, um den Agenten zu beschreiben und dessen Verhalten und Eigenschaften strukturell zu rahmen. Dazu gibt es viele prophetische Meinungen und Ansätze, wie man das am besten macht. Hierzu lohnt sich eine eigene Recherche. Ich habe noch weitere Informationen via AGENT.md und USER.md bereitgestellt, um den Agenten mit einem grundsätzlichen Konzept loszuschicken. Wenn man lokale Modelle verwendet, kann es sogar viel Sinn machen, die System-Prompts eines Modells zu überschreiben. Ein System-Prompt eines Claude Sonnet 4.5 sieht beispielsweise so
aus. Zig Konfigurationen konkurrieren miteinander oder ergänzen sich – so sind diese Dinge erstens eine Frage des Designs und zweitens eine Überlegung hinsichtlich der Kontext-Ökonomie.
Ok, aber angenommen, der Agent läuft und hat eine 1a Seele ;) – dann sollte man sich mit der Hermes-CLI, dem Dashboard und den verschiedenen Kommunikationskanälen vertraut machen. CLI und Dashboard sind für die Administration und das Debugging wichtig, während die Kommunikationskanäle (z. B. Telegram) für die Interaktion mit dem Agenten verwendet werden.
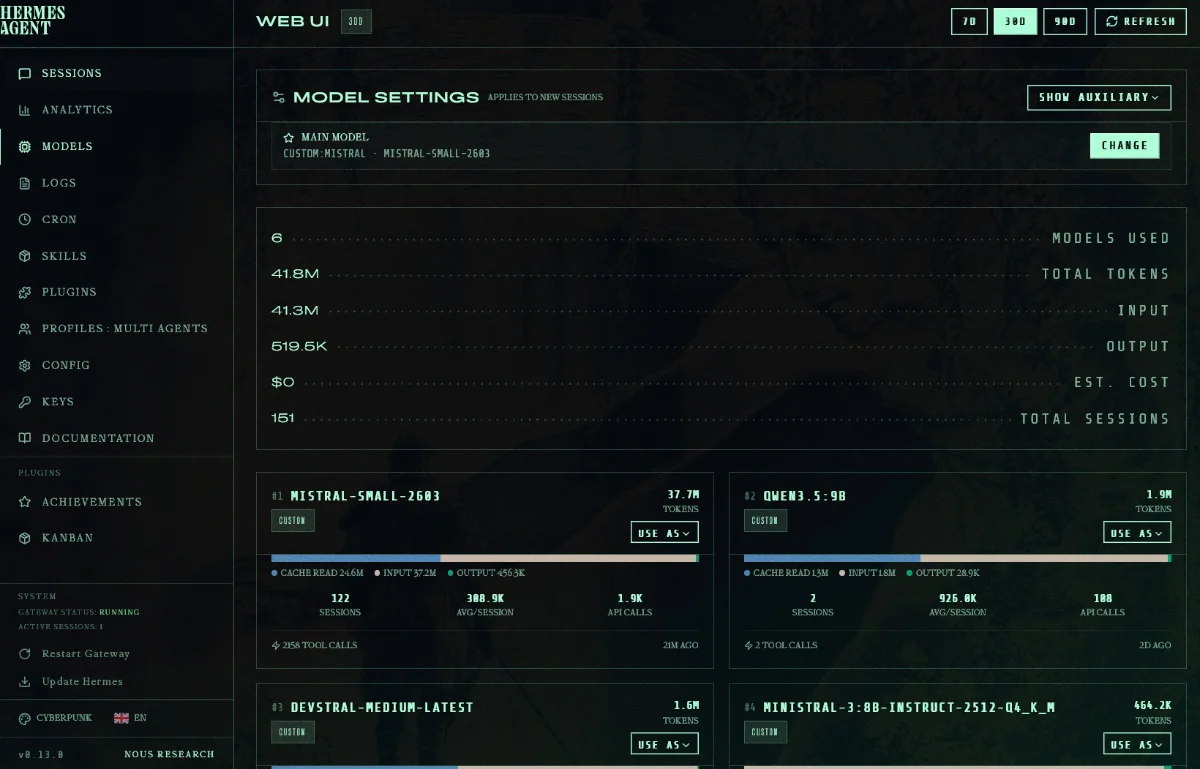
Hermes Dashboard
Da die Gesamtkonfiguration sehr umfangreich sein kann, bringe ich hier nur ein paar individuelle Aspekte mit hinein, die ich neben dem typischen Setup noch wichtig finde:
- Systematik, Hygiene und Struktur sollten früh mit dem Agenten verhandelt werden. Agenten müllen schnell alles zu, kommen durcheinander, lassen Dokumente verwaisen und verlieren den Überblick. Hier muss man früh klare Regeln aufstellen und Routinen sowie Strukturen etablieren. Je früher, desto besser.
- Wo liegen welche Daten und wie werden Berechtigungen verwaltet? Das ist eine wichtige Frage, die man früh klären sollte. Ob in einem gemeinsamen Obsidian Vault, ob in einer Vektor-Datenbank oder anderen Speicherorten – es sollte früh überlegt werden, wie Zugriffe und Berechtigungen verwaltet werden.
- Gute Daten, schlechte Daten … Ist es relevant, welche Daten der Agent verwendet? Ja, klar. Datenqualität, Kontext-Ökonomie und Datenverfügbarkeit sind wichtige Faktoren. Für den, der die Aussagen von Agenten liest, wird aber auch wichtig, wie verlässlich die Grundlage für die Aussagen ist. Somit müssen hier Konventionen, wie z. B. die Verwendung von Quellenangaben und Review-Prozesse, festgelegt werden. Ebenso wichtig ist die Verwendung von verlässlichen und aktuellen Datenquellen – eventuell gibt es eine Whitelist von vertrauenswürdigen Quellen.
- Ich finde es persönlich wichtig, Kontexte und Blaupausen zu modellieren, an denen sich ein Agent orientieren kann. Das kann z. B. ein „Playbook“ für einen perfekten Ablauf sein, ein Template für Nachrichten oder eine Struktur für Dokumente.
- Hermes kann präferierte Modelle und Fallback-Modelle für bestimmte Aufgaben konfigurieren. Das ist extrem gut, wenn es um Kostenkontrolle und Qualität der Ergebnisse geht. Es ist keine gute Idee, lokale Modelle häufig zu wechseln, wenn diese nicht alle parallel in den Speicher passen (was in der Regel nicht der Fall ist, zumal noch Luft für den Kontext existieren muss). Daher lieber ein grundsolides Modell wählen. Bei Cloud-Providern ist das anders. Hier ist wichtig, ein gutes Modell für den Job zu nehmen, Kosten zu kontrollieren und potenziell von Caching zu profitieren.
- Tools, die ich an einen Agenten anklemme, hoste ich gerne selbst. Eine nette Option ist etwa NocoDB, um gemeinsam spreadsheet-artig zu arbeiten. Der Bot via MCP, ich via UI.
Fazit: Wo Agenten heute glänzen – und wo sie scheitern
Wer den Hermes Agenten testet, stellt schnell fest: Wir haben es hier nicht mit linearer Standard-Software zu tun, sondern mit einem dynamischen System, das erzogen und gelenkt werden will. Agenten – und so auch Hermes – haben Limitierungen, produzieren auch Fehler und sind nicht gefeit vor Halluzinationen. Man sollte sie also noch nicht in Intensivstationen oder Fabriken einsetzen. Für manche Aufgaben kann man sie aber gut verwenden. Hermes erstellt solide morgendliche Berichte und News-Zusammenfassungen, Wettervorhersagen, hilft bei der Recherche und anderen Aufgaben. Kritische Aufgaben würde ich aber auch dem Götterboten noch nicht anvertrauen.
Die Sweet Spots: Was heute fantastisch funktioniert
- Asynchrone Triage & Research (Der „Overnight Worker“): Das ist die Paradedisziplin für Always-On-Runtimes. Wer Hermes abends mit einer SearXNG- und Playwright-Anbindung losschickt, um etwas in Erfahrung zu bringen oder mit weiteren Agenten einen Prototyp zu bauen, bekommt morgens einen Report oder eine Demo geliefert. In unterschiedlicher Qualität (je nach Systemzustand und Budget). Der Agent arbeitet aber klaglos im Hintergrund, beißt sich durch Aufgaben und bearbeitet die angefragten oder via Cron-Job geplanten Dinge. Am besten nutzt man hierfür sogar die Cron-Jobs, eventuell das Kanban-Board oder konkrete Trigger, um sicherzustellen, dass Dinge wie geplant erfolgen. Ist man selbst nicht aufmerksam, passiert unter Umständen auch einfach nichts.
- Kollaborative Datenpflege über MCP-Schnittstellen: Das Zusammenspiel über offene Protokolle funktioniert. Ein Setup, bei dem der Agent via MCP strukturierte Tabellen (wie in NocoDB) pflegt, während der Mensch parallel über das Web-UI die Daten validiert, erhöht durchaus die Effizienz. Das Zusammenspiel aus harten Code-Regeln und der semantischen Logik des Modells greift hier gut.
- Der self-improving Skill-Loop für Standardprozesse: Genau hier schlägt die Stunde von Hermes. Für repetitive, administrative Pfade (z. B. das tägliche Auslesen bestimmter Logs, Formatieren und Ablegen) baut sich der Agent aus erfolgreichen Durchläufen eigene, wiederverwendbare Skills. Er optimiert seine internen Abläufe selbstständig und passt sich an. Hier muss ich aber offen gestehen, dass ich mehr erwartet habe. Ich habe selbst vor einigen Wochen einen OpenMonkey Agent implementiert, der diese Anpassungen etwas vielfältiger hinbekommen hat. Der Ansatz stimmt bei Hermes, aber ich hätte mir dennoch mehr gewünscht.
- Hermes nervt nicht: Das fand ich sehr positiv. Hermes nervt nicht rum mit Dingen, nach denen man nicht gefragt hat. Das lässt ihn zwar manchmal auch eher wie einen herkömmlichen Chatbot anmuten, aber man muss ihn eben beschäftigen, bis sich das ändert.
- Allround ausgestattet: Da fehlt nichts, was das Basis-Rüstzeug betrifft. Und trotzdem ist er (technische Kenntnisse vorausgesetzt) stark erweiterbar. Ein gutes Paket.
Die No-Gos: Davon solltest du (noch) die Finger lassen
- Kritische Systeme oder hochsensible Daten: Dem Agenten freie Hand zu lassen, um direkt in Kundendatenbanken zu schreiben oder autark Produktivcode zu mergen, ist russisches Roulette. Die fundamentale Nicht-Linearität des multidimensionalen Vektorraums bedeutet, dass eine nicht gewünschte Inferenz-Entscheidung fällt, ein nicht gewollter Output entsteht. Agents wie Hermes geben Individuen neue Skalierungsoptionen und eventuell Superpower, für die man aber trotzdem Vorsicht walten lassen muss. Für kritische Systeme und wichtige Prozesse in Unternehmen sollte man sicherlich auf chaotisch-probabilistische Ansätze aktuell noch verzichten.
- Ungebremste API-Dauerläufe im offenen Web (Der 1.000-Euro-Loop): Ein kleiner Logikfehler im Prompt oder Code, kombiniert mit einer unendlichen Pagination auf einer Website, und der Agent verfängt sich in einer rekursiven Endlosschleife. Nutzt man in diesem Moment teure Cloud-APIs statt lokaler Open-Weight-Modelle, verbrennt das System in wenigen Stunden hunderte von Euro. Strikte Token- und Zeit-Budgets sind Lebensversicherungen für den Geldbeutel. Generell können Agenten, und so auch Hermes, aber teuer werden. Wenn für 100 % triviale Dinge das weltbeste Frontier-Modell benutzt wird, dann ist das nicht nur teuer, sondern auch nicht sinnvoll für die Gesellschaft. Smarte und ökonomischere Ansätze sind wichtig, Hermes bietet hier schon gute erste Ansätze. Etwa die feinere Modell-Einstellung (in meinem OpenMonkey Agent habe ich das ähnlich gemacht, aber auf Vorhersagebasis).
- Auch Hermes würde ich nicht shoppen schicken … Agenten, die in irgendeiner Weise mit der Außenwelt interagieren können, können Informationen leaken, Unerwartetes tun oder Schaden anrichten. Wenn sie mit hinreichend Möglichkeiten ausgestattet werden, können sie Dinge kaufen und verkaufen. Ich würde das in den allermeisten Fällen sicherlich aktuell keinem Agenten anvertrauen, da eine hohe Wahrscheinlichkeit besteht, dass die Pain/Gain-Ratio nicht stimmt.
- Freestyle-Kommunikation nach außen: Einen autonomen Agenten direkt und ohne Filter E-Mails oder Slack-Nachrichten an Kunden schreiben zu lassen, ist eine schlechte Idee. Ohne perfekt austarierte Leitplanken neigen Agenten bei komplexen, emotionalen oder mehrdeutigen Anfragen dazu, im Ton zu verrutschen oder Details schlicht zu halluzinieren. Reputation oder Authentizität entfaltet sich nicht durch die Hilfe von Agenten.
Hermes: ein solider und (tendenziell) angenehmer Vertreter der vermutlich unaufhaltsamen Agentifizierung
Am Ende zeigt auch das Experiment mit dem Hermes Agenten eines ganz deutlich: Wir bewegen uns weg vom Zeitalter der Applikationen, die wir per Klick befehlen, hin zu Systemen, die wir kultivieren müssen. Ein Agent spiegelt die Struktur wider, die man und die Umwelt ihm auferlegt. Wer etwa die Agenten-Umgebung im Docker-Container sauber isoliert, seine Prompts diszipliniert über Dokumente wie die SOUL.md pflegt und für eine nachhaltige Datenhygiene sorgt, bekommt einen nützlichen Begleiter an die Seite gestellt. Wofür man das nutzt, bleibt für viele oft noch offen. Ich finde, das liegt in der Natur der Phase, in der wir uns befinden.
Wir stehen am Anfang dieser Veränderung, nicht am Ende. Aber wer die Dampflok-Mentalität ablegt und lernt, mit der chaotischen Software und dem produktiven Unvorhersagbaren umzugehen, kann heute bereits lästige To-dos delegieren und neue Aufgaben entdecken.
