
Semantische Präzision: Warum Botschaften in der Agentic Era eine neue Architektur brauchen
Man kann nicht nicht kommunizieren – auch nicht mit KI-Agenten
In einem früheren Beitrag haben wir bereits beleuchtet , wie sich die digitale Suche von der klassischen Suchmaschine (SEO) hin zur Antwort-Maschine (AO) verschiebt. Doch während AO die strategische Frage beantwortet, wo wir stattfinden wollen, stellt die Agentic Era eine neue, tiefere technische Anforderung an uns: Wie präzise ist das Signal, das wir aussenden?
Paul Watzlawicks erstes Axiom der Kommunikationstheorie besagt, dass jedes Verhalten Mitteilungscharakter hat. Wenn ein KI-Agent – sei es Perplexity, Gemini oder eine autonome RAG-Pipeline – Ihre Website scannt, „kommuniziert“ jede Zeile Ihres Codes.
Das Problem: Die meisten Websites kommunizieren derzeit vor allem eines - semantische Entropie.
In der Informationstheorie ist das Verhältnis von Signal zu Rauschen (Signal-to-Noise Ratio) eine fundamentale Größe. Wenn wertvolle Informationen unter einer Schicht aus technischem Overhead, komplexen DOM-Strukturen und redundantem Code begraben liegen, entsteht eine messbare Reibung. Nennen wir diesen Effekt der semantischen Reibung für unsere weitere Betrachtung einfach: Noise Tax.

Noise Tax in der agentischen Rezeption
Semantic Gap: Die kognitive Last der Maschine
Während SEO vs. AO den Paradigmenwechsel im Nutzerverhalten beschreibt, adressiert die Agent Experience (AX) die technische Schnittstelle. Hier klafft der Semantic Gap bzw. die semantische Kluft: Menschen denken in Layouts, LLMs prozessieren Sequenzen von Token.
Wenn ein Agent auf 85% „Rauschen“ (Boilerplate-Code, Tracking-Skripte, Inline-SVG-Pfade) stößt, steigt natürlich die kognitive Last des Modells. Wissenschaftliche Studien wie „Lost in the Middle“ (Stanford et al.) belegen, dass die Fähigkeit von LLMs, korrekte Informationen zu extrahieren, drastisch sinkt, wenn das relevante Signal in einer Flut von irrelevantem Kontext untergeht. Ein schlechtes Signal-Rausch-Verhältnis führt zu einem “schlechtem Empfang des Signals” und letztlich zu Halluzinationen und Fehlern.
Die zwei Säulen eines AX-ROI: Effizienz und Präzision
Hat die Agent Experience einen Return On Invest? Ja.
Die Optimierung der Agent Experience ist kein technischer Selbstzweck. Die Noise Tax wirkt sich auf zwei Ebenen unmittelbar auf Ihren ROI aus:
1. Die Effizienz-Ebene: Die Token-Ökonomie
Für jede KI-Anfrage fallen Kosten an, die fast ausschließlich über das Token-Volumen abgerechnet werden. Die Kosten werden an den Benutzer eines Modells weitergereicht. Wenn ein Agent 10.000 Token verarbeiten muss, um eine Information zu finden, die eigentlich nur 100 Token umfasst, zahlt der Betreiber des Agenten (oder das System) bzw. der Benutzer also eine Ineffizienz-Prämie.
Ich habe ein schlankes Audit-Tool Monkey-Audit erstellt, das diese Ineffizienz-„Steuer“ pro Website quantifiziert: Ein durchschnittlicher Agent-Crawl auf einer conceptmonkey Seite (z.B. einen Post auf conceptmonkey.de) verursacht z.B. (geschatzt) Token-Kosten von ca. $0.0155. Was hier zunächst eventuell nach wenig klingt, summiert sich bei tausenden täglichen Indexierungen zu einem signifikanten Compute- und Budgetfresser. Auf anderen Webseiten, die ich zum Test des Tools überprüft habe, sind die durchschnittlichen Token-Kosten sogar deutlich höher. Überrascht war ich von dem Test des Wikipedia-Artikels Existenzielles Risiko durch künstliche Intelligenz , der Audit hatte z.B. folgendes Ergebnis:
...
TOKEN COST ANALYSIS (Noise Tax)
────────────────────────────────────────────────────────────
Efficiency Grade: C
Token Estimates (1 token ≈ 4 chars):
HTML Tokens: 83.389
Markdown Tokens: 42.038
Wasted Tokens: 41.351 (50% noise)
Est. API Cost: $0.1668 per page
Recommendation:
Moderate noise (50%). Consider optimizing HTML or providing llms.txt.
Der Deutschlandfunk-Artikel „Kunst kann Diktatoren stürzen“ bringt geschätzte Kosten von $0.2881 per page auf die Waage. Diese Kosten sind nicht faktisch und variieren von Modell zu Modell, Provider zu Provider, geben aber einen Eindruck davon, dass Webinhalte Nebenkosten verursachen.
Kontext: In dem Monkey-Audit Scoring fliessen Noise-Bewertungen mit einer Gewichtung von 30% in die Gesamtbetrachtung ein.
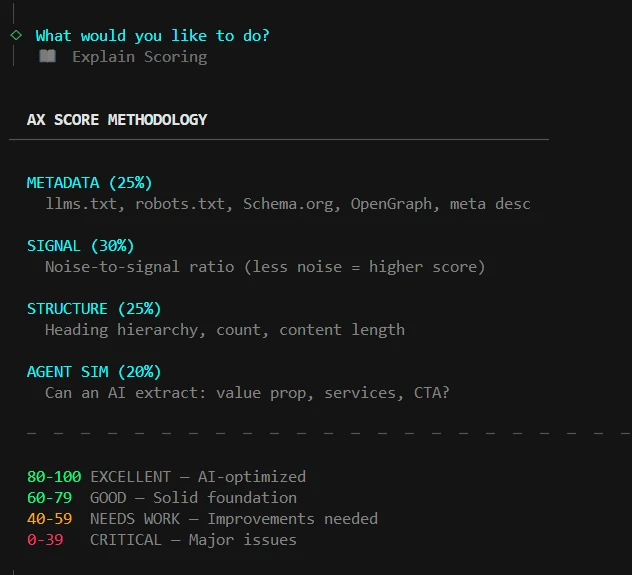
Scoring Dimensionen in Monkey-Audit
2. Die Sichtbarkeits-Ebene: Signal-Isolation und Konfidenz
Weit gewichtiger als die direkten Kosten ist die Präzision der Antwort. Je sauberer das Signal isoliert ist, desto höher ist die Konfidenz des Agenten bei der Empfehlung Ihrer Marke.
- Präzision statt Volumen: In der Kommunikation mit Agenten gewinnt nicht der längste Text, sondern die präziseste Information.
- Recommendation-Quality: Agenten agieren als neue Gatekeeper. Sie empfehlen bevorzugt jene Quellen, die sich ohne Ambiguität verarbeiten lassen.
ROI-Optimierung
Eine Optimierung der Agent Experience kann Ihr ROI steigern. Aber es kommt auf die strategische Dimension an, die einem Angebot zugrundeliegt. Es spielen jedoch ökonomische und kommunikative Faktoren eine Rolle, die zunächst unabhänggig von der strategischen Seite sind. Die Beschaffenheit von Inhalten erzeugt Kosten im agentischen Web. Viele dieser Kosten werden von Konsumenten letztlich getragen und sind entweder direkt in Token-Kosten oder impliziten Compute-Kosten übersetzbar. Das rein visuell geprägte Web wird damit in mehrfacher Hinsicht unnachhaltig und kostspielig. Die zweite ROI-Ebene hat mit der Signalpräzision und der Konfidenz zu tun. Existieren Ihre Botschaften im agentic Web so wie erwartet, wird eine Dienstleistung empfohlen und erreichen Sie mit digitalen Inhalten die damit verbundenen Ziele?
Audit Fallbeispiele
Mit Monkey-Audit wurden verschiedene Seiten analysiert, um die Ergebnisse zu validieren und die Effekte des Noise-Taxes zu quantifizieren.
Beispiel 1: spiegel.de
Ein Test ging auf spiegel.de - dort fiel mir auf, dass hier erwartungsgemäß viel “Noise” existiert und keine LLM-Optimierung vorgenommen wurde. Der Grund hierbei könnte in einer defensiveren Strategie zu sehen sein, die das eigene Content-Angebot gegen unerwünschte Zugriffe absichert.
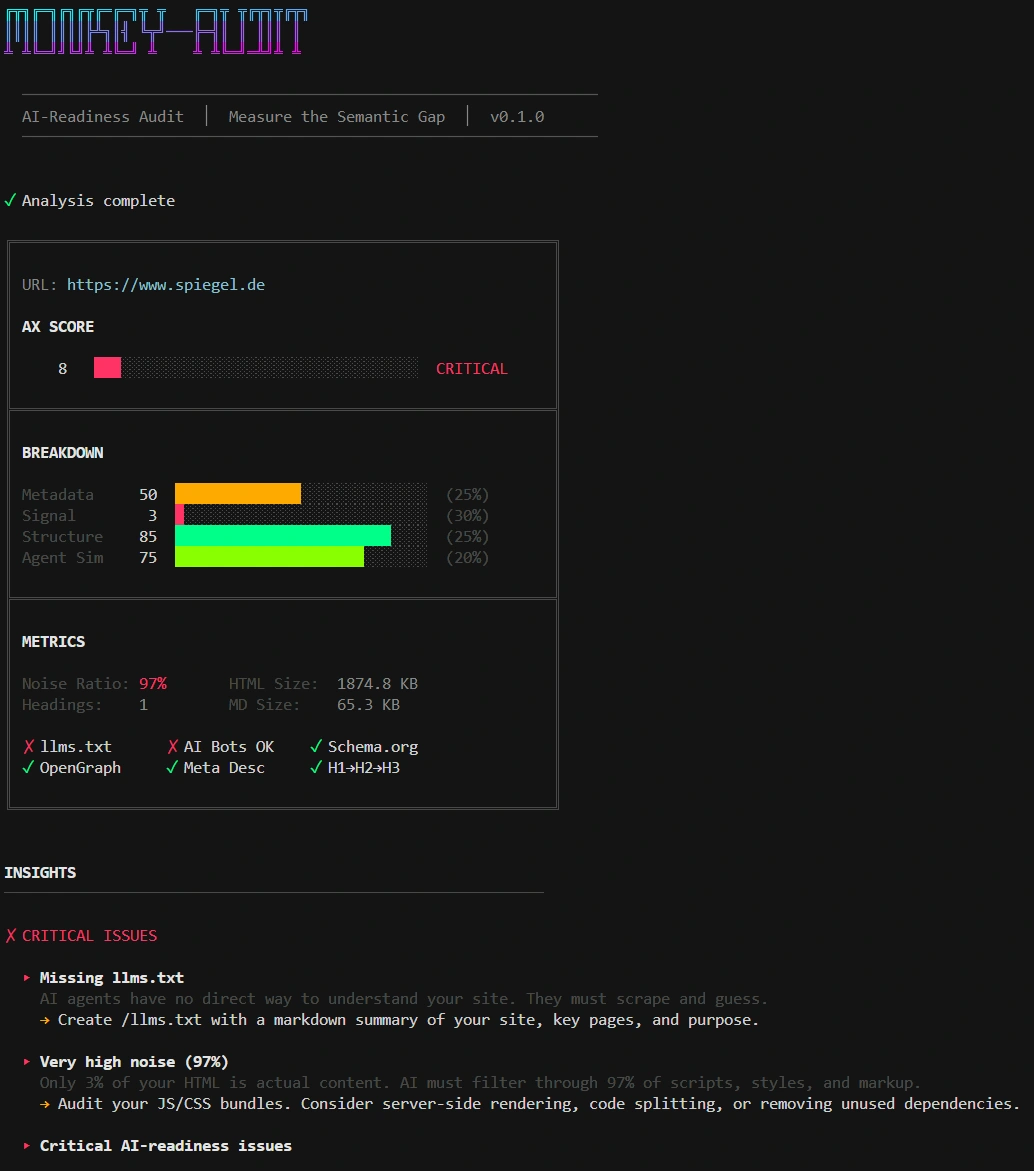
Spiegel.de Audit lässt Defensiv-Strategie vermuten
Beispiel 2: conceptMonkey.de
Ein einfaches Audit der conceptMonkey Startseite ergab, dass ich viel CSS und JS Friction produziert habe, was die Agent Experience zunächst einmal negativ (aufgrund eines ungünstigen Signal-Noise-Verhältnisses) beeinflusst. Für mich ist die visuelle Erfahrung menschlicher Besucher jedoch wichtiger als Agenten-Wahrnehmung, deshalb nutze ich Metadaten und sonstige Maßnahmen, um die Störgeräusche bis zu einem bestimmten Grad auszugleichen.
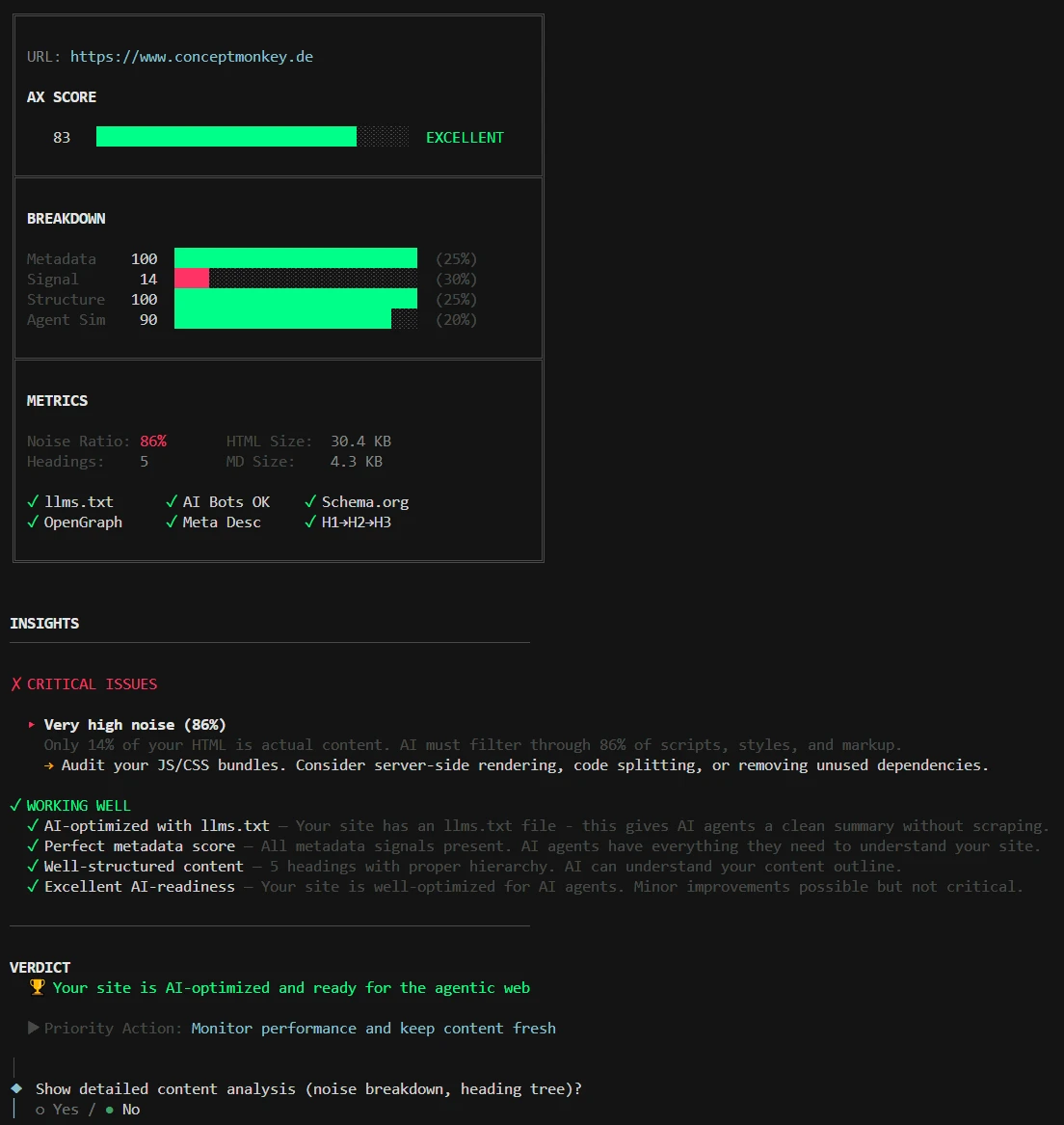
conceptMonkey.de Audit zeigt CSS und JS Friction
Vermessung der Web-Welt bringt noch keine Klarheit
Mir fiel auf, dass unterschiedlichste Seiten in den Audits auch sehr unterschiedliche Ergebnisse erzielen. Dies betrifft verschiedene Dimensionen des Audits, auf die man hier nicht detailliert eingehen kann. Interessant ist auch, dass verschiedene Inhalte einer Website oft sehr unterschiedliche Ergebnisse erzielen (also z.B. eine Startseite und ein Blog-Post der selben Domain). Das lässt eventuell auf eine hohe Inkonsistenz bei der Erstellung bzw. eine fehlende Systematik schließen.
Die Beweggründe im Umgang damit, wie Inhalte im Agenten-Web ausgestaltet werden, sind sehr unterschiedlich und hängen mitunter von dem jeweiligen Geschäftsmodell ab. Denn nicht jeder hat ein Interesse daran, dass Modellentwicklung, RAG-Nutzer und KI-Agenten sich jeden aufwändig erstellten Inhalt zu eigen machen. Doch auch hier gilt, dass sinnvolle Defensivstrategien dann auch systematisch umgesetzt werden sollten, soweit dies überhaupt geht.
Mein bisheriger Eindruck ist insgesamt, dass viele Inhalte noch (wenn überhaupt) für das klassische Web optimiert sind und die Agent Experience bislang bei vielen noch nicht im Fokus steht. Viele Websites berücksichtigen SEO und die menschliche Interaktion, aber sind nicht für das Agentic Web konzipiert oder umgerüstet.
Systemische Orchestrierung: Signale isolieren
Die Lösung liegt nicht in mehr alleine in Content, sondern in der präzisen Architektur Ihrer Daten. Systemische Orchestrierung soll hier bedeuten, dass jedes Signal – vom HTML-Tag bis zum globalen Metadatum – auf die gleiche „Wahrheit“ einzahlt, um die Autorität Ihrer Marke im Agentic Web nicht zu verwässern.
Harold D. Lasswell (1948) formulierte etwas, das ich in meinem Studium der Medienwissenschaften viele Jahre später lernen musste und auch in diesem Medienumbruch immer noch für relevant halte.
Wenn Sie einen digitalen Kanal wie eine Website für die Vermittlung von Botschaften (auch) an LLMs und Agenten nutzen, z.B. um ein Angebot für die KI-Suche aufzubereiten, dann sollte dies auch systematisch erfolgen und überprüft werden.
Die Basis der Orchestrierung
Identitäts-Anker (JSON-LD & Schema): Wir nutzen strukturiertes Markup nicht nur für Google-Snippets, sondern zur Entity-Etablierung. Durch die Verknüpfung mit externen Knowledge-Graphs (Wikidata, LinkedIn) geben wir Agenten einen festen Bezugspunkt für Ihre Autorität.
Strukturelle Symmetrie: Ein „Handshake“ zwischen semantischem HTML und Metadaten. Wenn die H1 einen “Apfel” verspricht, die JSON-LD eine “Birne” beschreibt und das llms.txt die “Orange” liefert, muss die semantische Konsistenz dringend reviewed werden. Abweichung kann zum „Authority Decay“ führen und KI stuft die Information als weniger vertrauenswürdig ein.
Cross-Page-Harmonisierung: Vermeidung von semantischer Verwässerung. Metadaten sollten über alle Unterseiten hinweg harmonisiert werden, um sicherzustellen, dass die Kern-Expertise (z. B. „Anbau von Äpfeln“) nicht durch widersprüchliche oder veraltete Legacy-Inhalte in einen falschen Kontext überführt wird.
Chunk-Optimierung: Inhalte können stärker modularisiert und bereitgestellt werden, so dass sie für RAG-Pipelines optimal extrahierbar sind. „Atomic Content Units“ (ACU) können so berücksichtigt werden, dass sie auch beim Zerlegen (Chunking) mehr von dem übergeordneten Kontext bewahren und etwa Halluzinationen entgegenwirken.
Kontext-Files (llms.txt): Der VIP-Kanal für Agenten. Diese bündeln den Kontext und die Struktur der Seite in einer Form, dass die Störgeräusche (~ Noise-Tax) erheblich reduziert werden und letztlich auch die Rechenlast (Compute) minimiert wird.
Checkliste zum Audit Ihrer Website
Tipp: Überprüfen Sie Ihre Website einfach mal auf die Effizienz Ihrer agentischen Kommunikation. Folgende Punkte sind hier hilfreich …
I. Technisches Fundament (The Handshake)
Context-Discovery: Existiert eine llms.txt im Root-Verzeichnis, um Agenten eine explizite Roadmap zu geben?
Crawler-Zugang: Sind KI-Agenten in der robots.txt explizit zugelassen oder ausgesperrt?
Schema-Validität: Ist das JSON-LD Markup (z. B. für Organization, Service oder Product) fehlerfrei und für LLM-Parser optimiert?
II. Signal-Qualität (~ Noise Tax)
Noise-to-Signal Ratio: Wurde das Verhältnis von technischem Boilerplate zu echtem Content optimiert, um den „Noise Tax“ (Token-Waste) zu minimieren? Benutzen Sie technische Grundlagen, die wenig Störgeräusche verursachen?
Code-Präzision: Sind inline-Styles, Skripte und komplexe SVG-Pfade ausgelagert, um das Context-Window des Agenten nicht unnötig zu fluten?
Token-Effizienz: Ist die Sprache präzise genug, um die relevante Information bei minimaler Token-Anzahl zu liefern?
III. Strukturelle Integrität (RAG-Readiness)
Semantische Hierarchie: Folgt die Heading-Struktur einer strikten Logik (H1 → H2 → H3), um das Dokument für Maschinen einfach gliederbar zu machen?
Chunk-Isolation: Sind Kerninformationen in „Atomic Content Units“ organisiert, die auch nach dem Zerschneiden (Chunking) durch eine RAG-Pipeline ihren Sinn behalten?
IV. Narrative Kohärenz & Trust (Authority Alignment)
Entity Trust: Sind die Informationen durch externe Reputation-Signale und korrekte Zitationen auf Drittplattformen verifizierbar?
Semantic Fit: Stimmen die Versprechen in den Metadaten (Title/Description) mit dem tatsächlichen Content auf der Seite überein?
Fazit: Man kann nicht nicht kommunizieren
… die Frage ist jedoch, ob Kommunikation im agentischen Web noch so erfolgen kann wie im klassischen Web.
Noise Tax ist eine Gebühr, die viele vermutlich unfreiwillig entrichten, weil sie ihre digitale Kommunikation noch nicht auf die Anforderungen der Agentic Era angepasst haben. Während AO dafür sorgt, dass wir Teil der Antwort sind, sorgt AX dafür, dass die Antwort präzise und kanaloptimiert erfolgen kann.
Indem Sie Signale isolieren und Rauschen minimieren, schließen Sie eine semantische Kluft.
Die strategische Frage bleibt unabhängig von der formalen Herangehensweise: Ob Sie Ihre Inhalte vor KI schützen oder für KI optimieren, ist eine strategische Fragestellung. In jedem Falle hilft aber ein systematischer Ansatz.
- Wissenschaftliche Basis: Lost in the Middle: How Language Models Use Long Contexts – Die wegweisende Studie von Liu et al. (Stanford/Berkeley) zur Performance-Degradierung bei hohem Kontext-Rauschen
- Technische Validierung: Needle In A Haystack Analysis – Der Industriestandard zur Messung der Signal-Extraktionsqualität von LLMs
- Agent-Standards: llmstxt.org – Dokumentation des aufstrebenden Standards für maschinenlesbare Kontext-Files
- Tool-Überblick: Monkey Audit – Diagnostic Engine für Agent Experience (AX)
- Verwandter Artikel zur Agent Optimierung: Suchmaschine vs. Agent
