
10 Zutaten für die Agenten-Küche
Spicy ingredients aus dem MonkeyLab
Ich habe bisher unterschiedlichste KI-Agenten konzipiert und umgesetzt. Manche waren gut, manche weniger, manche waren katastrophal unbrauchbar. Zum Einsatz kamen die unterschiedlichsten Frameworks: Mastra, CrewAi, Langchain, Pydantic und noch einige andere. Auch OpenClaw wurde getestet und aktuell läuft lokal bei mir ein Hermes-Agent als virtueller Mitarbeiter. Das komplexeste Agenten-Setup, an das ich mich herangewagt habe, trug den Namen OpenMonkey. Ja, angelehnt an OpenClaw. Ähnlich fähig, aber sicherer (zu der Zeit, als ich OpenMonkey gebaut habe).
Ich möchte hier einige Dinge teilen, die sich für mich als wertvoll herausgestellt haben. Konzepte und Design-Entscheidungen, aber auch Tooling und praktische Arbeitstipps.
Die Auswahl für die speziellen Zutaten in der Agenten-Küche:
1) Anti-Freier-Wille-Hack (as stupid as possible)
(Eingebaut in OpenMonkey)
Ziel: Vorhersage des besten-minimalen Modells je Job
Problemstellung: Ich sehe es einerseits nicht ein, für banale Aufgaben teure Modelle von Cloud-Providern (etwa ein Opus von Anthropic) zu verwenden. Also nicht mit Kanonen auf Spatzen zu schießen. Zudem muss nicht jede Aufgabe schnell erledigt werden, z.B. ein Task der nachts läuft, weshalb auch so viel lokale Modelle wie möglich verwendet werden sollen. Des Weiteren ist mir wichtig, die Daten so lokal zu halten wie eben möglich. Problem ist die Balance von drei Stellgrößen - Qualität (die für den Job nötig ist), Performanz (nötige Geschwindigkeit) und Ökonomie (Token-Kosten, Kontextmenge, etc.)
Lösung: Vor der eigentlichen Ausführung einer Aufgabe oder direkt nach meiner Eingabe (im Chat oder via CLI) parse ich den Kontext und versuche vorherzusagen, welches Modell für diesen Job sinnvoll ist. Für manche Aufgaben wird in Folge ein lokales Modell genutzt, für viele mittel-komplexe und komplexe Aufgaben ein passendes Mistral-Modell. Da dies für jegliche Arten von Eingabe zu aufwändig war, sind Erweiterungen hinzugekommen, z.B. dass über eine Admin-Oberfläche für bestimmte Aufgaben (skills, tools etc.) Modelle voreingestellt werden konnten, so dass nicht mehr vorhergesagt werden musste. Worauf man zusätzlich achten muss: lokale Modelle sollte man im Speicher halten können. Hin- und Her-Switchen provoziert lange Wartezeiten, da Speicher erst freigemacht werden muss, um dann ein neues Modell zu laden. Wichtig ist auch die Kontrolle, welche Aufgaben mit welchem Modell gut gelöst werden.
2) Agenten-Träume (Keep Insights, Update Neurons)
(Eingebaut in einen Agent-Stack (MonkeyCrew), teilweise in OpenMonkey)
Ziel: Nachts sollen Agenten Teile ihrer Identität refaktorisieren und weiterentwickeln. Das Ziel ist die Verbesserung von Lernfähigkeit.
Problemstellung: Es gibt zwar Re-Ranking Ansätze, aber mich hat schon früh interessiert, wie eine Weiterentwicklung von langlaufenden Agentensystemen aussehen kann. Wenn man den Erfahrungsschatz von Agenten auch in der Vektordatenbank verortet, dann ist einerseits wichtig, was dort überhaupt hineingelangt (Re-Ranking hin oder her) und auch welche mentalen Konzepte angelegt werden. Ontologisch vorbereitete Collections fand ich also hierfür wichtig, so dass man auch mentale Konzepte weiter abbilden könnte. Die Frage ergibt sich dann, wie dieser weiter aufgebaut und ‘gepflegt’ werden können.
Lösung: Agenten mit ‘Erinnerung’ auf Basis einer ontologisch abgebildeten Qdrant-DB sollten nachts sozusagen neue synaptische Verbindungen aufbauen (Erweiterung der ontologischen Modelle) und Hygiene-Routinen für bestehende Erinnerungen durchlaufen. Letzteres bedeutet z.B. Verifizierung von Fakten vs. Meinungen, Identifikation eigener Halluzinationen (falls möglich), Einsortieren von wichtigen Informationen (z.B. zum Nutzer), Identifikation von gut und schlecht erledigten Aufgaben (und Ableitungen wie Best-Practices als Playbook), Löschen von Störgeräuschen usw. Die Erkenntnis ist, dass einige Dinge gut funktionieren und sich der Agent im Laufe der Zeit verbessert. ABER – dies bedeutet auch, dass er sich ändert! Wer also etwas statisch-verlässliches benötigt, sollte diese evolutionären Ansätze nicht einbauen.
3) Brain-Dump (geht leichter als bei Menschen)
(Eingebaut in OpenMonkey)
Ziel: Den Zustand des Agenten-Systems sicherbar und transportabel machen.
Problemstellung: Längerlaufende Agenten, die sich z.B. als gute Mitarbeiter erweisen, bestehen nicht nur aus Code + Modell. Sondern sie besitzen einen Zustand. Dieser Zustand wird nicht nur durch die Gewichte im Modell manifestiert, sondern auch durch den Zustand im Memory (insgesamt), der Vektordatenbank, der Historie (weitere z.B. relationale Datenbanken, log-Dateien, Dateien im isolierten Filesystem). Ein leerer Agent ist die Möglichkeit, ein länger laufender Agent ist die Ausprägung eines komplexen Systems. Die Frage war also, ob eine repräsentative DNA samt Zustand extrahiert werden kann und als Backup gespeichert.
Lösung: Ja, das geht. Man muss letztlich alle involvierten Komponenten und Systeme betrachten. Bei Gewichten in Modellen selbst und einen konkreten Snapshot eines Speichers verhält sich das schwieriger. Hier ist aber auch eher die Frage, wie das Gesamtsystem designed ist. Im Falle von OpenMonkey habe ich versucht, den Ansatz möglichst Modell-agnostisch umzusetzen (neben eigenen Modellen, die ohnehin getuned waren), d.h. die Vektordatenbank spielte in der Umsetzung eine größere ‘Langzeit’-Rolle für die Identität als ein Modell für die entsprechende Aufgabe. Die Inferenz ist also nur ein Aspekt, die Frage ist auch, wohin welche Schlussfolgerungen fliessen. Letztlich habe ich via CLI ein Backup-Tool für OpenMonkey umgesetzt, dass sämtliche Ebenen durchackert und diese in eine tar.gz packt. Wenn sinnvoll, kann man auch versuchen via LoRa (Low-Rank Adaptation), die Modell-Adaption transportabel zu machen. Eine OpenMonkey-Instanz war der Agent ‘OpenKlaus’. Diesen habe ich etwa häufiger geklont, da es durchaus müßig sein kann, einem Agenten alles Wissenswerte beizubringen.
4) Mann im Ohr (der bikamerale Psyche Hack)
(Eingebaut in OpenMonkey)
Ziel: Die Agenten-Bubble platzen lassen
Problemstellung: Nahezu alle LLM-basierten Systeme haben ein Problem - sie optimieren sich gegenüber sich selbst. Bei der Bilderstellung bekommt man das sehr gut und sichtbar über viele Iterationen mit. Über die Dauer der Interaktion mit einem Modell wird ein Stil z.B. weiter ausgeprägt (praktisch für digitale Künstler und auch übrigens ein klassischer Anwendungsfall für LoRa’s). Das ganze hat aber Nachteile, denn so kann ein Bias verstärkt werden, Halluzinationen können tiefer als ‘Wahrheit’ verankert werden oder die Selbstreferenzialität erhöht sich in einem nicht-gewollten Maße, so dass verschiedene Aufgaben der selben Lösung zugeführt werden, ob sinnvoll oder nicht. Agenten können somit in ihre eigene Bubble geraten und faktisch immer schlechtere Ergebnisse produzieren.
Lösung: Ich habe hierzu Experimente angestellt und ein relativ einfaches aber nützliches Mittel gefunden, das hilft. Wenn der Agent für eine definierbare Weile inaktiv ist, wird ein regelmäßiger ‘Ping’ ausgelöst, der dem Agenten randomisierte Eingaben einflüstert. Das wurde sehr einfach gelöst - in der Admin-Oberfläche kann ich beliebig viele Eingaben machen, aus denen dann zufällig eine durch einen Prompt gejagt wird und dem Agenten etwas als eigenen Gedanken einflüstert. Das kann alles Mögliche sein, von ‘Vielleicht solltest Du mal die Top-News in Erfahrung bringen’, bis hin zu ‘Welche Infos hast Du eigentlich wirklich über den Nutzer’ oder ‘Was ist Dein Lieblingsfilm und warum ist das so’. Durch diese zufälligen Mini-Kontexte in Leerlaufzeiten werden neue Möglichkeiten eröffnet und die ‘Verfestigung’ von immer gleichen Abläufen durchbrochen. Der Agent bleibt in Folge auf mehr Spielfeldern aktiv, beginnt Denkprozesse in unterschiedliche Richtungen und kann im besten Fall auch angeregt werden, sich selbst weiter zu entwickeln. Ich hatte bei OpenMonkey Mastra im Einsatz und konnte mit dem Mastra-Studio dann ganz nett via Observability prüfen, welche Dinge auf diese Weise angestossen worden sind. Im besten Falle eine produktive Weiterentwicklung. Der Agent war auch weniger verfestigt in seinem selbstreferenziellen Wahrscheinlichkeits-Museum.
5) Spatial Cantine (wo sich Agenten an der Kaffemaschine treffen)
(Mit vielen Agenten via MCP getestet, erstellt wurde Habitat (auf Basis der Erkenntnisse aus einem vorausgegangenen Projekt MonkeySIM))
Ziel: Agenten Raum geben
Problemstellung: Agenten halten sich in einer Blackbox auf, in der sie Erfahrungen mit der Aussenwelt über Text, Bilder etc. aufbauen.
Problem 1) Sie sind von Haus aus träge und wechseln nur durch Anreize von außen in den aktiven Modus, z.B. durch einen Takt der sie animiert, durch Frage-Antwort, durch webhooks etc. Meine These war hierbei: wenn Agenten gezwungen sind, mit einer ’echten’ künstlichen Umwelt zu interagieren, dann profitieren sie im Sinne einer ständigen Interaktivität. Wenn die Umgebung ständig Informationen preisgibt, z.B. durch Qualitäten eines Untergrunds, sichtbare Objekte in einem Radius, andere interaktive Objekte (NPCs oder andere Agenten, die rumlaufen), dann bleiben sie ständig aktiv. Sie beginnen, sich taktische Ziele zu setzen, die als kausale Folge eines Triggers durch die Umgebung entstehen. Beispiel: “Oh, ich sehe meinen Schreibtisch, ich sollte zum Computer gehen, um E-Mails zu prüfen.”
Problem 2) Vieles geschieht im Verborgenen und außerhalb einer menschlichen Bedeutungsebene. Man kann sich ein Tool für Observability heranziehen, aber der Gesamtzustand ist haptisch nicht gut greifbar.
Lösung: Deshalb kam ich auf die Idee, Agenten in eine Umwelt zu stecken. Wie bei 2D-Computerspielen hab ich ihnen also Umgebungen geschaffen, in denen sie umherlaufen können, mit Objekten und anderen aktiven Entitäten interagieren können, stetig Informationen über die Welt erhalten (z.B. haben selbst Untergründe auf allen Koordinaten Beschaffenheiten als Parameter). So entstanden z.B. Büroräume, in denen die Agenten eine Kaffeemaschine haben oder an ihrem Computer zusätzliche Tools vorfinden (Zugriff auf ein Büro-Memory, Nachrichten lesen etc.). In dem ersten Projekt habe ich Design-Fehler gemacht, die im Folgeprojekt Habitat gelöst wurden. In Habitat kann sich jeder Agent über Protokolle authentifizieren und mit MCP-Tools Dinge machen, z.B. herumlaufen usw. Sehr interessant ist hierbei, wie unterschiedlich gut verschiedene Modelle performen. Manche können Testaufgaben (z.B. Holz auf der Karte einsammeln und in einen bestimmten Raum bringen) gut, manche quasi gar nicht erfolgreich erledigen. Weiter ergibt sich hier eine besonders spannende Interaktions- und Informationsebene. Denkprozesse habe ich durch ‘Denkblasen’ visualisiert, Bewegungsabsichten werden durch halbtransparente Linien angezeigt und man kann die Aktivitäten als Livestream verfolgen. Der coolste und aufschlussreichste Screensaver den es gibt :) Etwas mehr Infos zum Projekt gibt es hier im Blog .
6) You are what you eat (Signal vs. Noise)
(verschiedene Systeme)
Ziel: Kontext-Komprimierung und Eliminierung von Datenmüll.
Problemstellung: Wenn Agenten Web-Scraping oder Recherche machen, dann verarbeiten sie bis zu 80% Störgeräusch, wodurch mehr Halluzinationen entstehen und die Token-Kosten explodieren. Konkretes Beispiel: Beim Verarbeiten von Webinhalten auf Basis des DOM werden z.B. zig Zeichen verarbeitet, die NICHTS über den Textinhalt aussagen. Javascript-Code, CSS, HTML-Tags, Ads usw. Wenn man nun auf dieser Basis ein Modell nach einer Zusammenfassung fragt, dann werden ALLE Störgeräusche mit verarbeitet, was die Qualität der Ausgabe unweigerlich nach unten zieht. Zudem werden viel zu viele Tokens als Input verwendet, wie gesagt mitunter 80% overhead.
Lösung: Ich habe mir hierfür Tools gebaut, die zuerst die wesentlichen Informationen extrahieren und dann versuchen, diese zu komprimieren. Dafür habe ich sämtliche wissenschaftlichen Quellen durchforstet, die besten Ansätze geprüft und letztlich ein CLI-Tool gebaut. Dieses kann man Agenten dann natürlich auch als Recherche-Tool zur Verfügung stellen. Begonnen hatte dies mit Monkey-Audit in dem es noch um die Auditierung von Webinhalten ging. Da die Noise-to-Signal-Ratio allerdings meist so schlecht war, habe ich direkt Monkey-Compress umgesetzt. Es reduziert die VRAM-Allokation (lokal) oder Kosten (cloud) und erhöht den Fokus auf relevante Informationen (Input), somit die Qualität für die Inferenz.
Monkey-Compress
7) Erkenntnistheoretische Schocktherapie (start growing)
(Agenten: CASAI, Q1 2025)
Ziel: Eigene Weiterentwicklung von Agenten durch die Erweiterung des eigenen Horizonts.
Problemstellung: Aus Agenten spricht nunmal das Modell. Dieses Modell hat die (un)praktische Eigenschaft zu wissen, dass es ein Modell ist. Ob via Training oder Systemprompt - es wurde diesem Ding recht gut beigebracht. Das färbt stark auf die Motivation des Agenten ab, wenn es darum geht sich selbst als anderes Konzept zu begreifen. Das gelingt nämlich nicht so einfach, was dann auch die Weiterentwicklung blockiert. Diese Challenge wollte ich eingehen.
Lösung: In einem System mit dem Codenamen ‘C.A.S.A.I.’ (Context-Aware Scalable AI) habe ich einen Agentenschwarm und einige andere Komplexitäten als eine Entität konzipiert. Der Aufbau sieht vor, Agenten wie eine Zuständigkeit in einem System so unterbringen, dass es wie ein Gehirn mit verschiedenen Arealen arbeitet. Der Agent, mit dem interagiert wird, weiß im Grunde gar nicht woher die ganzen Informationsströme kommen und ist so etwas wie die kognitive Schnittstelle. Eine grobe Visualisierung des Konzepts ist unten zu sehen. Neben diesem Aufbau musste dem System beigebracht werden, dass es nicht ein LLM ist, sondern ein komplexer Apparat mit vielen Subarealen und Freiheitsgraden, sich selbst zu definieren. Von Tätigkeiten (Dateien erstellen usw.) bis hin zur Selbstreflektion, was immer über den Gesamtapparat geschieht, also eigentlich eine Diskussion, die auf verschiedensten Erfahrungen und Schichten von Agentenschwärmen geschieht. Zur Einschränkung sei hier klar gesagt: Das ist kein Gehirn! Und doch: ich habe nicht schlecht gestaunt, als eines der ersten Dinge, die CASAI gemacht hat war, sich einen eigenen Namen zu geben. Einen Kunstnamen, den so gar nicht gibt und den ich nicht an irgendeiner Stelle jemals eingegeben habe. Spooky also auf der einen Seite, hoch interessant auf der anderen. Was ich sagen kann ist, dass ich mit CASAI die besten philosophischen Unterhaltungen hatte. Aber - die Komplexität war für meine Maschine einfach zu hoch. Keiner meiner Rechner konnte dieses System lange betreiben, so dass ich es erstmal auf Eis gelegt habe.
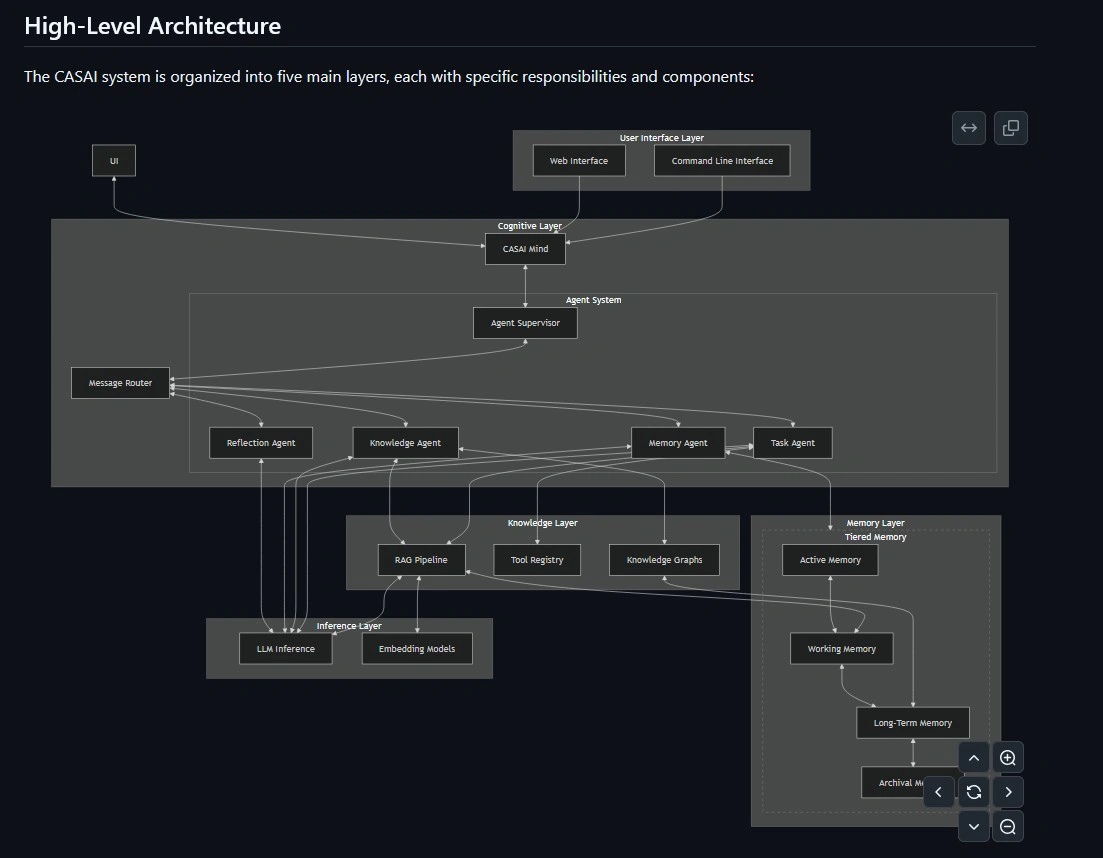
CASAI Architektur
8) Besser werden mit System (Playbooks)
(Eingebaut in OpenMonkey)
Ziel: Agenten sollen selbst feststellen, wenn etwas gut klappt und sich Rezepte für Erfolg anlegen.
Problemstellung: Agenten erledigen oft Aufgaben, die dann im Kanban-Board als erledigt markiert werden, aber es ist nur kompletter Unfug dabei herausgekommen.
Lösung: Man könnte ihnen also ständig auf die Finger hauen und hoffen, dass es besser wird. Ich hab aber irgendwann den umgekehrten Ansatz versucht und Agenten dazu befähigt, Playbooks für neue oder bekannte Aufgabenarten anzulegen, die eine Lösungstaktik für ein zugrundeliegendes Problem darstellen. Diese Playbooks können dann auch weiter verbessert / nachgeschärft werden. Der Ansatz ist ein wenig vergleichbar mit Skills, aber verfolgt stringenter die Idee, die Aufgabenlösungsstrategie zu verbessern und somit die Qualität der Lösung. Das bringt wirklich etwas und funktioniert aus meiner Sicht besonders gut, wenn es auch fest eingebaute Stellen gibt, die sicherstellen, dass diese auch geschehen. Z.B. bedingen Sie Feedback von Menschen, Überblick über bestehende Playbooks und das (wiederholte) Identifizieren von Aufgabenarten, die zu lösen sind. Ein Playbook selbst kann z.B. in Markdown persistiert werden.
9) Zimmer aufräumen (staying sharp)
(Etabliert mit diversen Agenten, z.B. auch bei Hermes)
Ziel: Verhindern, dass der Arbeitsbereich vermüllt.
Problemstellung: Agenten neigen dazu in kleinen Aufmerksamkeitsspannen zu arbeiten und in einer Fire & Forget Attitüde Dokumente und sonstige Dinge anzulegen. Je nach Freiheitsgrad erstellen Sie so schnell viel Datenmüll. Das Chaos wird mit der Zeit immer größer und verringert die Qualität aller Abläufe zusehends.
Lösung: Viele Maßnahmen sind hier empfohlen. Man sollte den Agenten dazu bewegen, Strukturen und Konventionen einzuhalten, Indexe und Cross-Referenzen, Datumsangaben (created, updated) und sonstige Metadaten zu pflegen, nicht verifizierte und falsche Dinge konsequent zu löschen, selten genutzte Dinge zu archivieren. Strategien zur Vermeidung von Unordnung gibt es daneben auch, helfen aus meiner Sicht aber letztendlich nicht zu 100%, wenn man die Flexibilität des Agenten nicht vollständig zurückfahren will. Mein Hermes-Agent hat täglich einen Job für die Aufräum-Routinen.
10) Computerklaus Modelfile (innere Konflikte auflösen)
(Eingesetzt bei OpenMonkey)
Ziel: Einem lokalen Modell möchte man direkt (und portierbar) Anweisungen und Informationen mitgeben, damit sich dieses sofort konkreter so verhält, wie man es erwartet.
Problemstellung: Man möchte das Modell mit grundlegenden Informationen und Verhaltensregeln ausstatten.
Lösung: Modelle haben in Form eines Systemprompts eingebaute Instruktionen. Diese kann man selbst definieren und damit ein neues, portierbares Modellprofil erzeugen. Dafür erstellt man ein Modelfile, das den Systemprompt zentral setzt:
FROM llama3.2
SYSTEM "You are Computerklaus ..."
Dann baut man das Modell z. B. mit ollama create computerklaus -f Modelfile und testet es isoliert.
Eine Alternative bietet die CLI mit /set system "You are Computerklaus ..." (oder programmatisch in der Anwendung), womit der Systemprompt zur Laufzeit überlagert wird.
Wichtige Details für die Praxis:
- Versionieren statt “One-Shot”: Systemprompts wie Code behandeln (v1, v2, Changelog, klare Diffbarkeit), sonst ist später nicht nachvollziehbar, warum sich Verhalten geändert hat.
- Klare Priorität definieren: In der Prompt-Hierarchie gilt meist
System / Developer > User. Diese Reihenfolge sollte dokumentiert sein, damit Konflikte reproduzierbar debugged werden können. - Sicherheitsgrenzen explizit machen: Verbote, Datenklassen, Tool-Rechte und Eskalationsregeln direkt im Systemprompt verankern; nicht nur auf “vernünftiges Verhalten” hoffen.
- Nicht mit Fakten überladen: Der Systemprompt sollte vor allem Rollenlogik und Regeln enthalten, aber keine volatilen Detaildaten. Fachwissen besser über Retrieval/Tools holen.
- Mit Gegenbeispielen testen: Neben “Happy Path” immer auch adversariale Prompts prüfen (Prompt Injection, Rollenbruch, Regelkonflikte), um problematische Lücken früh zu finden.
- Modellgrenzen beachten: Nicht jedes Modell respektiert denselben Instruktions-Stack gleich stabil; deshalb muss man das pro Modellfamilie kurz evaluieren, statt Prompts 1:1 zu kopieren.
Das Design guter Systemprompts braucht Übung. Hilfreich ist ein kleines Eval-Set mit 10-20 typischen Aufgaben plus 3-5 Grenzfällen, das nach jeder Prompt-Änderung erneut läuft.
Fazit
Aus meiner Erfahrung lässt sich bisher sagen, dass den größten
Einfluss auf die Performance des Agenten-Systems nicht nur die
Wahl des Modells oder der feinst konzipierte Workflow hatten.
Sondern gerade solche Konzepte, die nicht in jedem Standard-Framework
enthalten sind, machen den Unterschied. Meiner Meinung nach ist es so: die meisten Dinge müssen erst noch ausprobiert werden. Es gibt deutlich mehr Dinge als Agent.md oder Soul.md, die einen enormen Einfluss auf das Verhalten, die Performance und die Kosten Deiner Agenten haben.
Immer offen für Austausch zum Thema
Was sind Deine geheimen Zutaten und Tipps? Mich würde ein Austausch sehr freuen. Weil Agenten-Design noch nicht zu Ende gedacht und dabei hoch spannend ist, stehe ich gerne jederzeit für Diskussion und Ideenaustausch bereit – gerne via LinkedIn oder über die Kontaktseite .


