Monkey-Audit
SCOPE
Problemstellung
- Websites optimiert für Menschen, noisy für KI-Agenten
- SEO-Metriken versagen in der Welt von RAG und Agentic Reasoning
- Fehlender maschinenlesbarer Kontext führt zu Problemen
- Standardmetrik für Agent Experience (AX) fehlt
- Systematik bei der Informationsarchitektur fehlt in diesem Bereich
Lösungsansatz
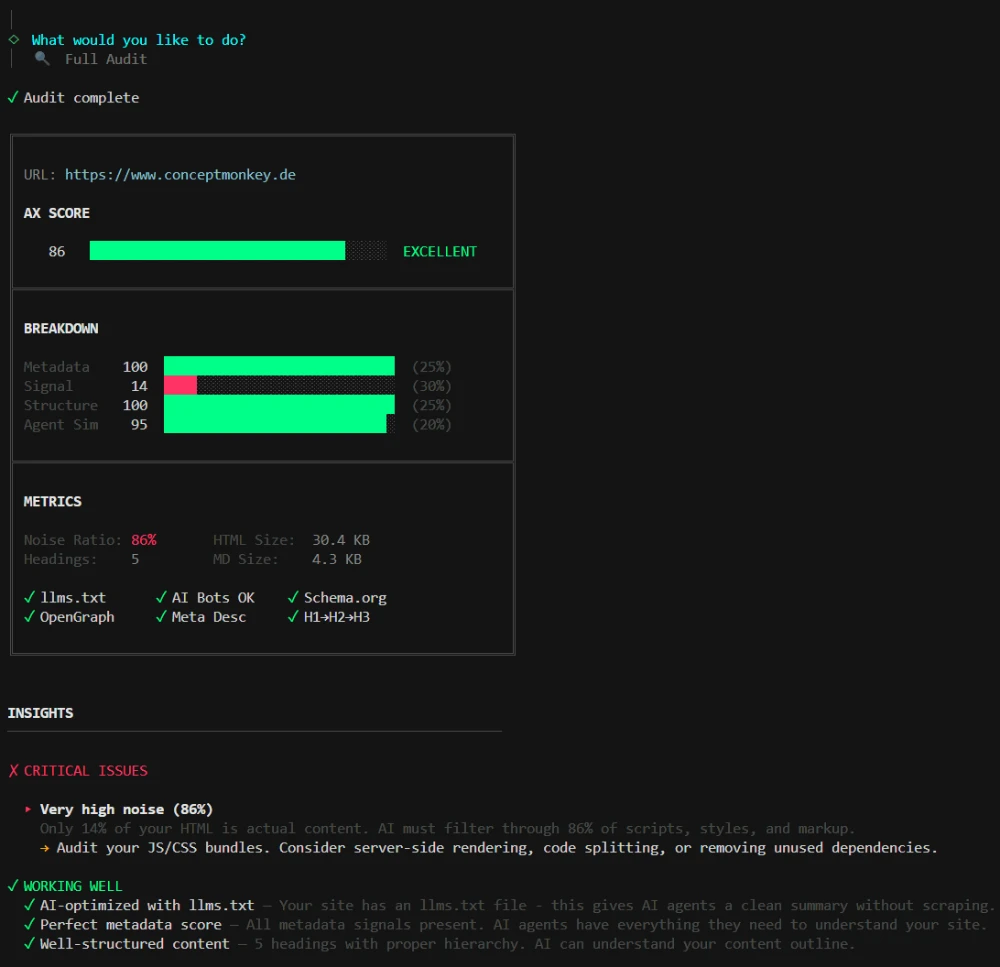
- AX Score Metrik: Metadata (25%) + Signal (30%) + Struktur (25%) + Agent Sim (20%)
- CLI-Tool für systematisches AX-Auditing aus Agent-Perspektive
- Lokale LLM-Integration (Ollama) für Agenten-Simulationen
- Terminal UI mit visuellen Score-Gauges und Exporten (JSON, Markdown, HTML)
- Ergebnis: Monkey-Audit CLI
Im Einsatz
- Node.js
- TypeScript
- Ollama
- Jina Reader API
- @clack/prompts
Ergebnisse
- v0.5 Prototyp in < 3h Vibe Coding Session entwickelt
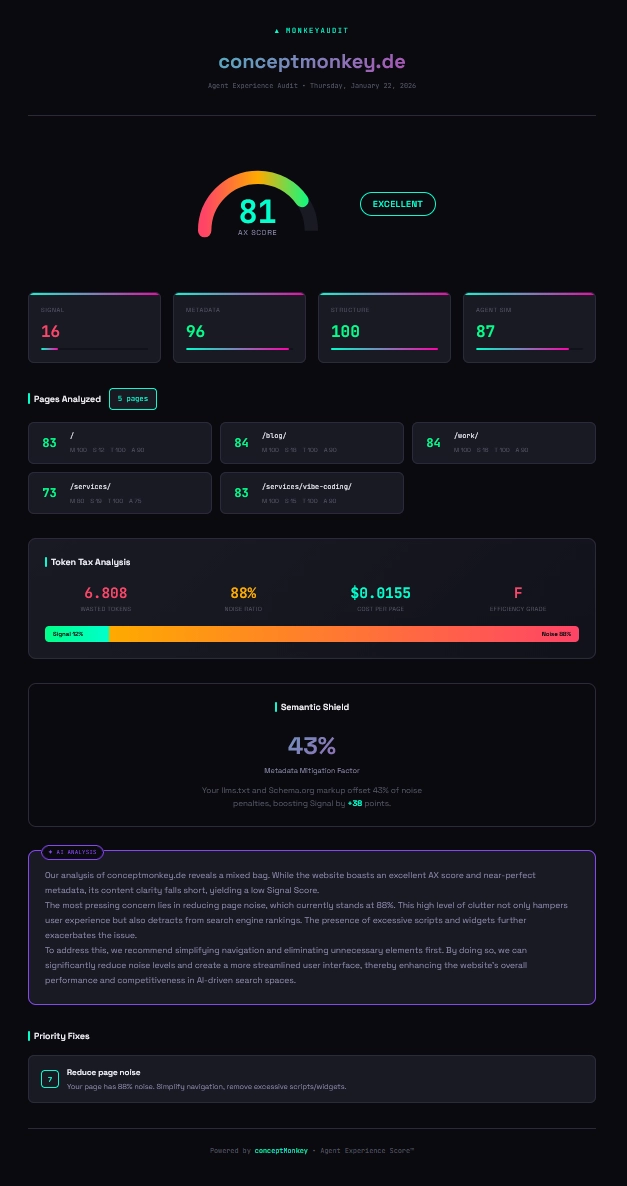
- AX Score 84/100 für conceptmonkey.de gemessen
- 76% Noise Tax durch Framework-Boilerplate identifiziert
- Metadaten-Strategie (inkl. llms.txt) validiert
- Diagnostische Basis für Systemische Orchestrierung geschaffen
Monkey-Audit: Diagnostic Engine für die Agentic Era
Wir befinden uns in einem Paradigmenwechsel. Die “Age of Discovery” verlagert sich von klassischen blauen Links hin zu Agentic Reasoning. Während Websites bisher für menschliche Augen und Legacy-Crawler optimiert wurden, bleiben sie für KI-Agenten wie Perplexity, SearchGPT oder Developer-Tools (Cursor/Windsurf) oft “opak”.
Mit Monkey-Audit haben wir im Monkey Lab ein Werkzeug geschaffen, das diesen Semantic Gap messbar macht.
Das Problem: Der blinde Fleck der Webentwicklung
Herkömmliche SEO-Metriken versagen in der Welt von RAG (Retrieval-Augmented Generation). Ein hoher PageSpeed-Score sagt nichts darüber aus, ob ein LLM den Kernwert eines Unternehmens zwischen Tausenden von Zeilen Boilerplate-Code findet. UI-Bloat und fehlender maschinenlesbarer Kontext führen zu Halluzinationen oder – noch schlimmer – zur völligen Unsichtbarkeit in agentischen Workflows.
Die Lösung: AX (Agent Experience) als Standard
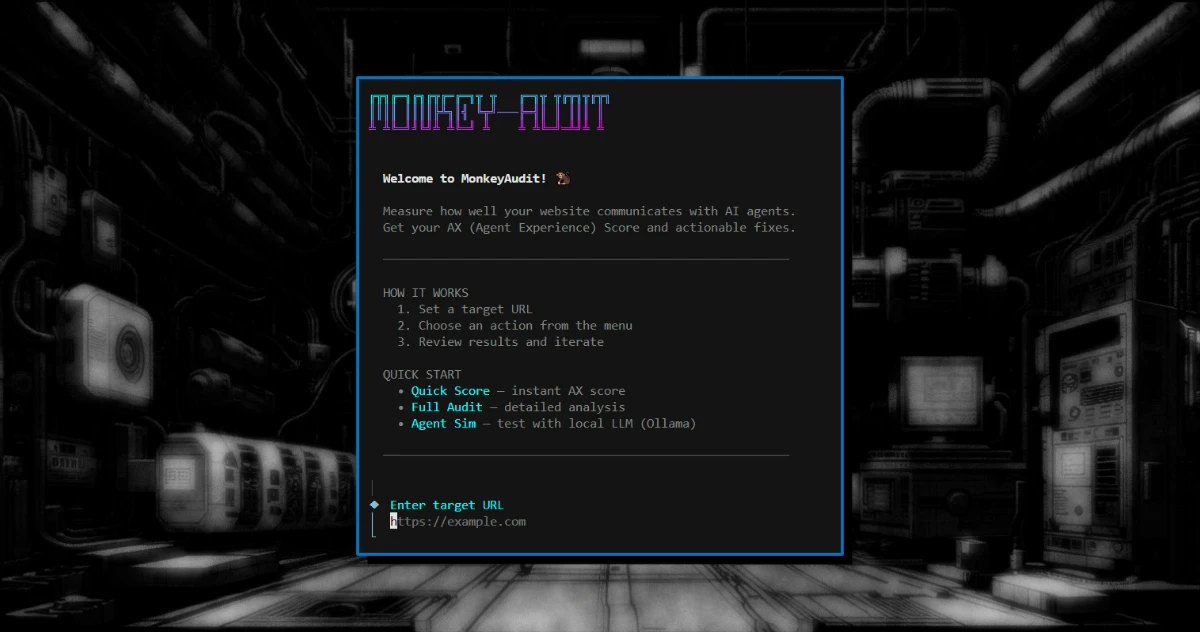
Monkey-Audit ist ein Node.js-basiertes CLI-Tool, das eine Website aus der Sicht eines Agenten auditiert. Es berechnet den AX Score (Agent Experience) – eine gewichtete Metrik aus:
- Metadata (25%): Vorhandensein von
llms.txt, Schema.org und präzisen Meta-Signalen. - Signal (30%): Das Verhältnis von echtem Content zu technischem Rauschen (Noise-to-Signal Ratio).
- Structure (25%): Die semantische Hierarchie für optimales Chunking.
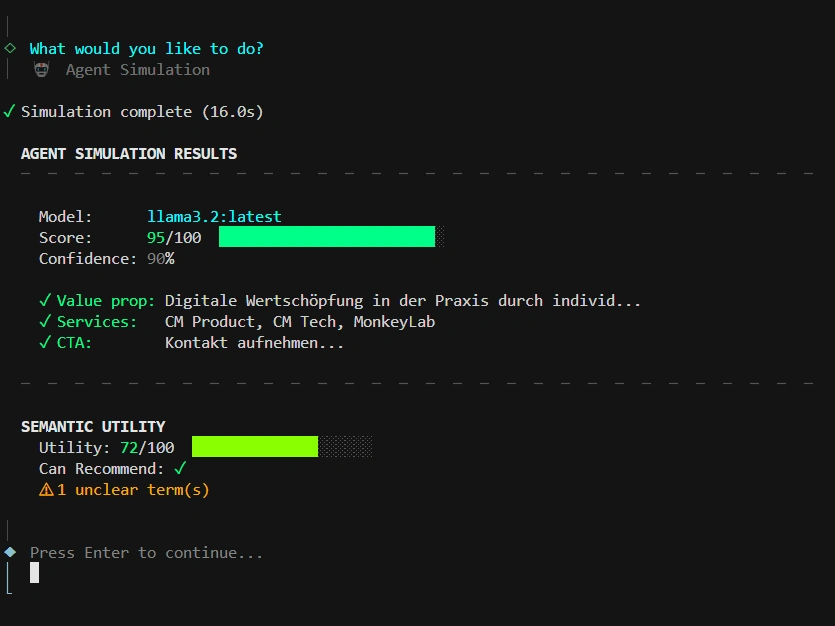
- Agent Sim (20%): Eine Live-Simulation via lokaler LLMs (Ollama), die testet, ob die KI das Value Prop und die CTAs tatsächlich extrahieren kann.
Monkey-Audit CLI Tool
Tech Stack & Vibe Coding
Das Tool wurde in einer intensiven Vibe Coding Session innerhalb von weniger als drei Stunden von der Idee zum funktionalen v0.5-Prototyp entwickelt.
- Runtime: Node.js / TypeScript 5.7
- Scraping: Jina Reader API Integration für sauberes Markdown-Parsing.
- Intelligence: Ollama Integration (Llama 3.2) für lokale, souveräne Agent-Simulationen.
- UI: Brutalist Terminal UI mit
@clack/promptsund Manga-inspirierten Score-Gauges.
Monkey-Audit scoring
Das Ergebnis
Natürlich habe ich Monkey-Audit direkt auf conceptmonkey.de losgelassen. Das Ergebnis: Ein AX Score von 84/100 (abhängig von den untersuchten Seiten, im Schnitt > 80). Während unsere Metadaten-Strategie und sonstige Maßnahmen bislang Bestnoten erzielt, offenbarte das Tool starke Störgeräusche, also ein “Noise Tax” von ~ 76% durch CSS und JS, durch die sich auch ein KI-Modell graben muss, bis die wesentlichen Informationen gefunden werden.
Nutzen im Monkeystack
Monkey-Audit ist eine gute Ergänzung im souveränen Monkeystack – die CLI ist eine diagnostische Grundlage für die Systemische Orchestrierung digitaler Assets und hilft bei der Entwicklung von digitalen Inhalten. Die Systematik im Ansatz hat die analytischen Vorgänge extrem geboostet. Der persönliche Bias, der bei Gestaltungsthemen immer mitschwingt, wird durch die Systematik neutralisiert. Insofern ist Monkey-Audit ein Instrument, das direkt nützlich ist und Schwachstellen aufdeckt.
Funktionalität
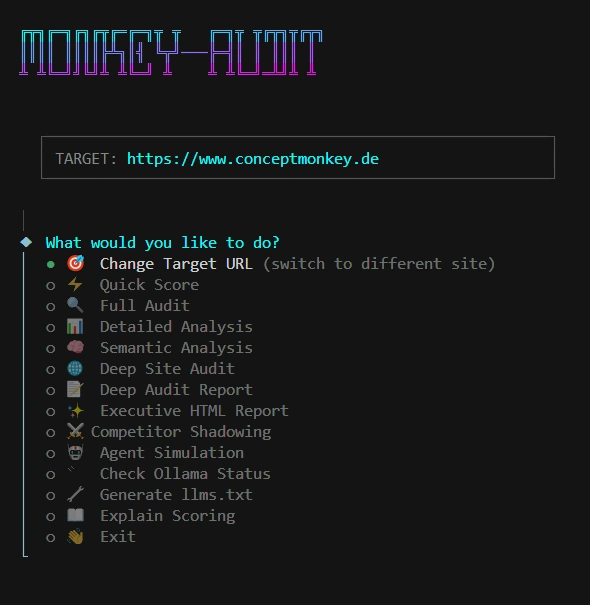
Core Audit
- 🐒 Wizard Mode: Geführter interaktiver Modus mit Session-State (
startcommand) - AX Score: Single 0-100 Metrik für AI-Readiness der Website
- Detailed Breakdown: Metadata, Signal, Structure, Agent Sim Subscores
- ☠️ Critical Failure: Wenn robots.txt AI-Bots blockt → Score sinkt auf 15%
Content Analysis
- Noise Analysis: Analysiert kommunikative Störgeräusche (Scripts, Styles, SVGs)
- Heading Tree: Visualisierung der Content-Struktur
- Q&A Detection: Findet FAQ-Patterns und fehlende FAQPage Schema
- Scannability Score: Listen, Tabellen, Paragraph-Längen-Analyse
- Indexability Check: Canonical Tags, noindex/nofollow Detection
- Page Type Detection: Auto-Detect für Blog, Service, Portfolio, etc.
- Schema Suggestions: Ready-to-use JSON-LD Code für Page Types
Semantic Analysis
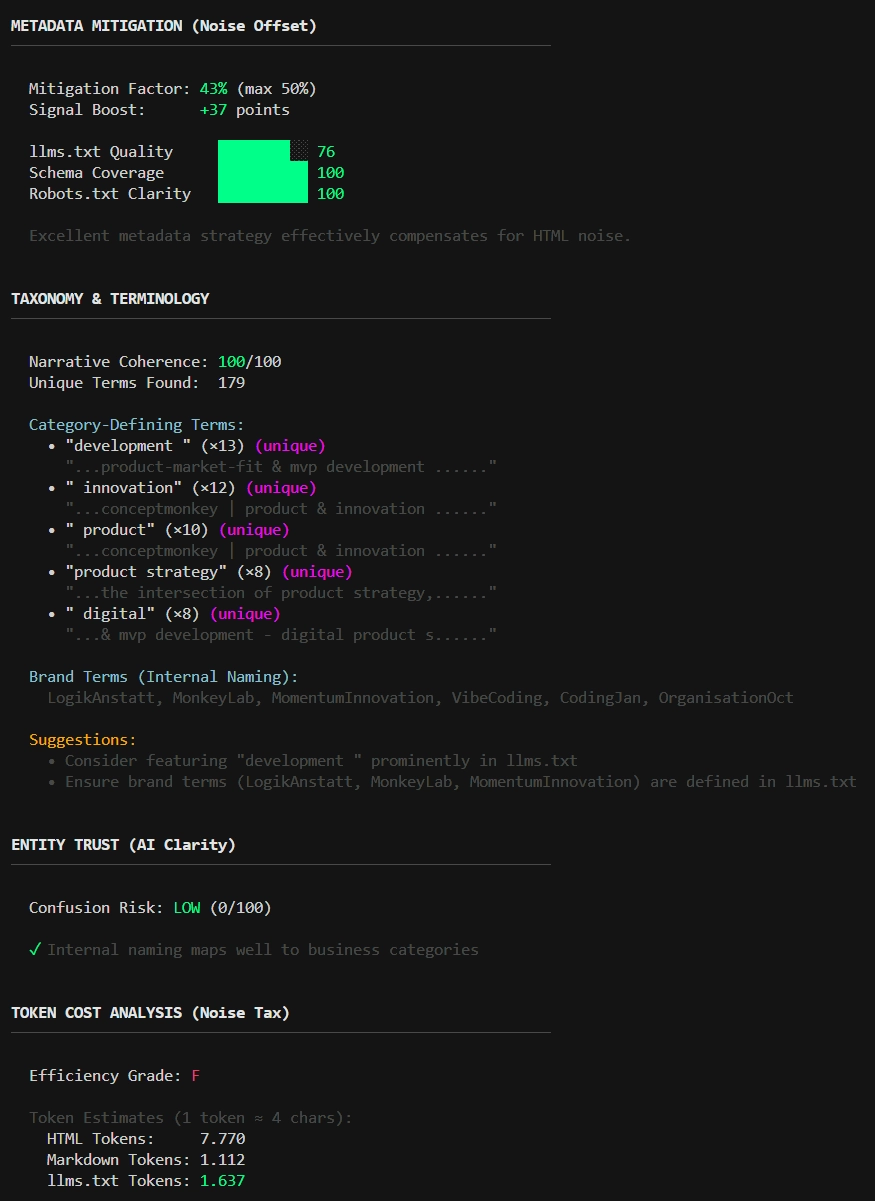
- Token Tax: Cost-per-Page Metrik zeigt “Noise Tax” in Dollar
- Metadata Mitigation: Wie gut llms.txt + Schema den Noise offsetten
- Taxonomy Analysis: Kategorie-definierende Terms, Narrative Coherence
- Entity Trust: Brand-Konsistenz, Contact-Info Qualität
- Semantic Utility: Bewertet, ob extrahierte Daten für AI-Recommendations actionable sind
AI Testing
- Agent Simulation: Testet AI-Verständnis mit lokalem LLM (Ollama)
- Live Agent Sim: Real-time LLM-Queries mit
--liveFlag
Commands & Output
- ⚡ Quick Score: Schneller Score-Check ohne Prompts (
scorecommand) - 📊 Full Report: Kombiniert alle Tests in einem Report (
reportcommand) - 🏥 HTML Executive Report: Visuelles Dashboard als HTML-File (
htmlcommand) - ⚔️ Competitor Shadowing: Side-by-side Vergleich (
vscommand) - 🔧 llms.txt Generator: Auto-generiert llms.txt (
fixcommand) - 📖 Explain: Erklärt AX-Score Methodik (
explaincommand) - Sitemap Deep Audit: Multi-Page Scan aus Sitemap (
--deep/--pages N) - JSON Export: Machine-readable Reports inkl.
raw_markdownfür RAG (--json --raw)
Ausblick
Mit Monkey-Audit bin ich noch nicht fertig ;) Für die lokale Entwicklung steht noch eine direkt-Integration in den Coding-Stack an, z.B. via MCP. Auf diese Weise kann schon während der Entwicklung von Inhalten auf deren AI-Readiness und die Informationsarchitektur geachtet werden. Evtl. wird das Projekt auf github unter MIT veröffentlicht, aber das ist aktuell noch nicht final entschieden.
Weitere Screenshots
Monkey-Audit: Lokale Agenten Simulation
Monkey-Audit: Semantic Gap Analysis